Représentation vectorielle et modèles transformer (ce n’est pas le film)
Explorez le modèle d'espace vectoriel et son rôle essentiel dans l'optimisation de la pertinence des résultats de recherche.
Sommaire
- 1Résumé rapide
- 2Points à connaître avant de commencer
- 3Qu’est‑ce que le modèle d’espace vectoriel ?
- 4Pourquoi ce modèle est‑il si efficace ?
- 5La révolution des transformers (sans effet pyrotechnique)
- 6BERT et le traitement bidirectionnel du contexte
- 7Synonymes et correspondance conceptuelle
- 8Longueur des documents et biais : pourquoi les articles longs semblaient favorisés
- 9Comment fonctionnent les bases de données vectorielles et l’indexation ?
- 10Récents constats sur la citation et l’importance des premières sections
- 11Tokens, budget de grounding et implications multilingues
- 12Conséquences pratiques pour la création de contenu et le référencement
- 13Dernières observations
Les systèmes de recherche d’information sont avant tout conçus pour satisfaire un utilisateur. Leur objectif principal est d’optimiser la pertinence des résultats retournés. Comprendre cette finalité guide la conception des données d’entraînement, des mesures de similarité et de la capacité des machines à interpréter des requêtes formulées en langage naturel.
Cet article fait partie d’une série consacrée à l’extraction d’information et aux fondements des systèmes de recherche moderne. Il se concentre sur les principes du modèle d’espace vectoriel et leurs implications pour le classement de documents, la vectorisation et l’évaluation de la similarité.

Image Credit: Harry Clarkson-Bennett
Résumé rapide
Dans le modèle d’espace vectoriel, la distance entre vecteurs reflète la pertinence ou la similarité entre documents ou éléments.
La vectorisation a permis aux moteurs de recherche de rechercher par concepts plutôt que par simple correspondance de mots. Il s’agit d’aligner des concepts, pas seulement des chaînes de caractères.
Les documents longs contiennent plus de termes et peuvent obtenir des scores plus élevés ; pour corriger ce biais, on applique des techniques de normalisation de la longueur des documents et on privilégie la pertinence.
Google et d’autres acteurs utilisent ces techniques depuis des années. Les principes sont robustes et largement applicables.
Points à connaître avant de commencer
Avant d’entrer dans le vif du sujet, voici quelques notions et outils fréquemment cités dans la littérature sur le traitement du langage et la recherche d’information. Vous n’avez pas besoin de les maîtriser parfaitement dès maintenant, mais il est utile de les reconnaître et de comprendre leur rôle.
TF‑IDF — sigle de term frequency–inverse document frequency, statistique classique qui évalue l’importance d’un terme dans un document au regard d’un corpus.
Similarité cosinus — mesure qui évalue le cosinus de l’angle entre deux vecteurs ; plus le cosinus est proche de 1, plus les vecteurs sont similaires.
Bag‑of‑words — représentation textuelle simple basée sur la fréquence de mots sans tenir compte de l’ordre.
Extraction de caractéristiques / encodage — méthodes qui transforment le texte brut en vecteurs numériques exploitables par des modèles.
Distance euclidienne — mesure géométrique de la distance entre deux points dans un espace vectoriel.
Doc2Vec — extension de Word2Vec destinée à encoder des documents entiers pour estimer leur similarité.
Qu’est‑ce que le modèle d’espace vectoriel ?
Le modèle d’espace vectoriel (souvent abrégé VSM) est un cadre mathématique qui représente des documents, requêtes ou autres unités de contenu sous la forme de vecteurs dans un espace à haute dimension. Chaque dimension correspond à une caractéristique (par exemple un mot, une phrase, un n‑gramme ou une caractéristique dérivée), et la position d’un document dans cet espace reflète son contenu sémantique.
Une fois les éléments représentés par des vecteurs, il devient possible de mesurer la distance ou l’orientation entre eux pour estimer leur similarité. Des mesures comme la similarité cosinus ou la distance euclidienne sont couramment utilisées pour calculer ces scores.
Ces modèles sont largement employés pour le classement de documents, la recherche par concept, l’extraction de mots‑clés et d’autres tâches d’information retrieval car ils structurent le texte de manière exploitables par des algorithmes.
Chaque terme reçoit un poids : s’il apparaît dans un document, son poids est non nul. Ces termes ne se limitent pas aux mots isolés — ils peuvent être des expressions, des phrases ou même des représentations de documents entiers.
Après l’attribution de poids aux éléments textuels, on peut scorer des documents en réponse à une requête et les comparer entre eux selon leur proximité dans l’espace vectoriel. Cette évaluation fondée sur le sens est appelée similarité sémantique et dépasse la simple correspondance lexicale.
Pour l’illustrer simplement : un document peut ne pas contenir exactement les mêmes mots que la requête mais exprimer des idées équivalentes ; le modèle d’espace vectoriel permet de capter cette équivalence conceptuelle.
Pourquoi ce modèle est‑il si efficace ?
Les machines fonctionnent mieux avec des représentations structurées. Les vecteurs à longueur fixe fournissent une entrée prévisible qui simplifie la classification, la recherche de voisins proches et les estimations statistiques. Le texte, en revanche, est intrinsèquement non structuré et variable ; la vectorisation transforme ce désordre en une forme utilisable.
À la différence du modèle booléen classique — qui récupère des documents sur la base d’opérateurs logiques (AND/OR/NOT) et exige souvent une correspondance littérale — le modèle d’espace vectoriel évalue la pertinence au sens large. Il ne nécessite pas une correspondance exacte des termes pour faire apparaître des résultats pertinents.
En pratique, cela signifie que le système peut prioriser des documents dont le sens général correspond mieux à la requête, plutôt que de favoriser uniquement ceux qui utilisent les mêmes lexies.
La révolution des transformers (sans effet pyrotechnique)
Les architectures basées sur les transformers ont profondément modifié la manière dont on calcule des représentations vectorielles. Contrairement aux méthodes statiques traditionnelles (par exemple Word2Vec), qui associent un vecteur unique à chaque mot, les transformers produisent des embeddings contextuels : la représentation d’un mot varie selon son contexte.
Autrement dit, un même mot aura des vecteurs différents selon la phrase qui l’entoure, ce qui permet de lever des ambiguïtés lexicales et d’améliorer la pertinence des rapprochements sémantiques.
Les transformers fonctionnent en attribuant des pondérations (mécanismes d’attention) aux mots en fonction de leur importance contextuelle pour la phrase ou le passage étudié :
Le modèle évalue l’importance relative des tokens d’entrée.
Il met davantage d’attention sur les mots qui apportent du contexte ou qui influencent fortement le sens.
Exemple : dans la phrase « Les dents de la chauve‑souris brillaient lorsqu’elle a quitté la grotte », le mot « chauve‑souris » est ambigu. Grâce au contexte (« dents », « grotte », « a quitté »), le modèle contextualisé infère correctement qu’il s’agit d’un animal, et non d’un équipement sportif.
BERT et le traitement bidirectionnel du contexte
BERT (Bidirectional Encoder Representations from Transformers) a popularisé l’idée de modéliser le contexte dans les deux directions. Au lieu d’examiner un mot uniquement depuis la gauche ou la droite, BERT considère l’ensemble de la séquence pour produire une représentation plus riche.
Cette capacité à analyser toute la séquence permet de mieux saisir les relations sémantiques et les intentions de recherche, ce qui a contribué à améliorer la compréhension des requêtes et la correspondance avec des documents pertinents.
Des variantes comme DeBERTa ont introduit des mécanismes supplémentaires (par exemple la représentation distincte de la signification et de la position) afin d’affiner encore l’interprétation du contexte.
BERT traite l’ensemble d’une séquence simultanément, ce qui permet d’appliquer le contexte à l’échelle d’un passage ou d’une page plutôt qu’à celle de quelques termes voisins seulement.
Synonymes et correspondance conceptuelle
Des systèmes comme RankBrain ont marqué un tournant : l’algorithme a commencé à relier mots et concepts plutôt que de s’appuyer exclusivement sur des correspondances littérales. Ces avancées ont rendu possible la remise en contexte automatique et la meilleure interprétation d’expressions inédites.
Plus récemment, des approches multimodales (par exemple MUM) étendent cette compréhension aux images et à d’autres formats, en traitant la sémantique sur plusieurs modalités et langues simultanément.
Longueur des documents et biais : pourquoi les articles longs semblaient favorisés
Historiquement, les documents plus longs avaient tendance à mieux performer dans de nombreux systèmes de recherche. Cela s’explique en partie par le fait qu’ils contiennent davantage de termes distincts, augmentant ainsi les probabilités de correspondance et les valeurs brutes de fréquence de terme (TF).
Deux catégories de documents longs :
Contenu verbeux répétant essentiellement les mêmes idées (ex. bourrage de mots‑clés).
Documents couvrant plusieurs sujets, où la requête ne correspond qu’à une section restreinte.
Pour atténuer ce biais, des méthodes de compensation de la longueur ont été développées, comme la Pivoted Document Length Normalization. Ce type de normalisation de la longueur ajuste les poids des termes afin que la pertinence prime sur la simple fréquence.
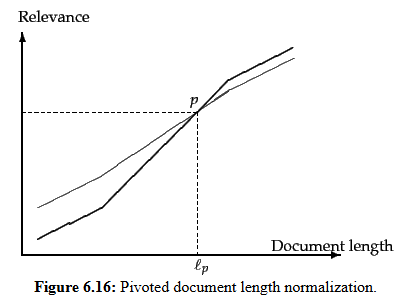
La normalisation pivotée rééchelonne les poids des termes autour de la longueur moyenne des documents (Image Credit: Harry Clarkson-Bennett)
La similarité cosinus est souvent privilégiée car elle met l’accent sur l’orientation des vecteurs plutôt que sur leur magnitude, réduisant ainsi l’avantage induit par la longueur d’un document. Un passage court et un long texte peuvent donc être considérés comme équivalents si leurs vecteurs pointent dans la même direction.
Comment fonctionnent les bases de données vectorielles et l’indexation ?
Vous n’avez pas besoin de connaître tous les détails d’un moteur vectoriel pour appliquer les principes dans vos contenus, mais il est utile de comprendre les grandes lignes. Les bases de données vectorielles créent des index spécialisés — souvent basés sur des structures d’approximate nearest neighbor (ANN) — afin de retrouver rapidement les vecteurs proches sans comparer chaque enregistrement.
Les choix techniques (indexation, précision vs performance, coût de calcul) déterminent l’équilibre entre rapidité, coût opérationnel et qualité des résultats. Les grands acteurs adaptent ces paramètres pour optimiser l’expérience utilisateur à grande échelle.
Récents constats sur la citation et l’importance des premières sections
Des analyses récentes montrent que, dans des réponses générées par des modèles de type LLM, une proportion importante des citations provient des premières sections des documents consultés. Par exemple, une étude a trouvé que ~44 % des citations utilisées par ChatGPT proviennent des 30 % initiaux d’un texte source, un phénomène parfois décrit comme un effet « rampe ».
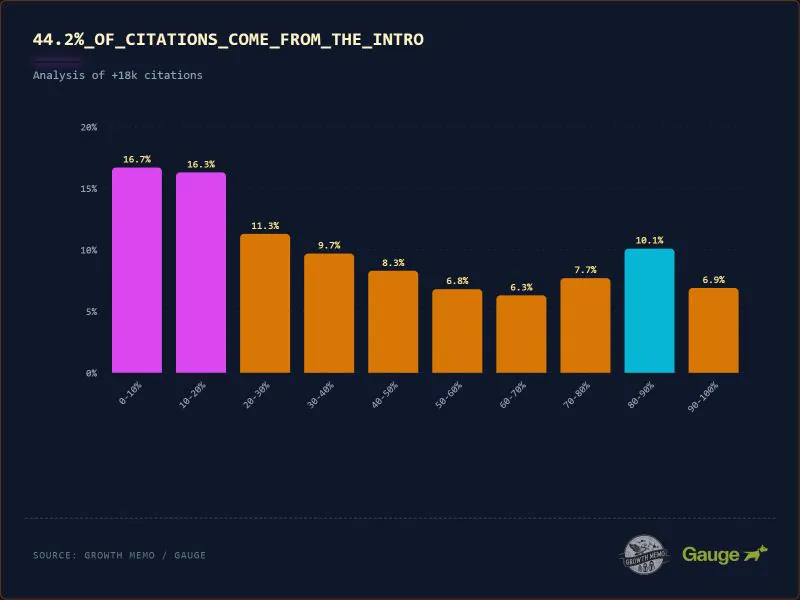
Image Credit: Harry Clarkson-Bennett
Ce constat renforce l’idée qu’il est souvent plus efficace de structurer l’information clé en tête de document plutôt que de compter sur la longueur totale pour capter l’attention d’un moteur ou d’un modèle.
Tokens, budget de grounding et implications multilingues
Dans les systèmes alimentés par des modèles de langage, le texte est converti en tokens (unités de base traitées par le modèle). Certains travaux indiquent qu’il existe un budget de « grounding » — une quantité maximale de texte source que le système peut intégrer efficacement pour générer une réponse. Par exemple, des estimations parlent d’un budget approximatif de 2 000 mots répartis entre les sources selon leur pertinence.
Au niveau des langues, la densité en caractères par token varie : l’anglais courant est relativement efficace (plus de caractères par token), tandis que d’autres langues ou formats (ex. tableaux Markdown) sont moins efficaces. Ces différences ont des conséquences sur les coûts de traitement et la qualité des résultats, notamment lorsqu’un fournisseur doit équilibrer précision et dépenses d’infrastructure.
Conséquences pratiques pour la création de contenu et le référencement
Les principes décrits ci‑dessus suggèrent des bonnes pratiques concrètes pour rédiger des contenus destinés à bien se positionner dans des environnements de recherche modernes :
Répondre précisément à la requête : fournissez l’information demandée rapidement et sans ambiguïté.
Placer l’information essentielle en tête (frontloading) : les modèles et les utilisateurs consomment souvent les premières secondes/paragraphes en priorité.
Désambiguïser : utilisez des indications contextuelles (entités nommées, données structurées) pour clarifier de quel concept il s’agit.
Soigner l’E‑E‑A‑T (Expérience, Expertise, Autorité, Fiabilité) : produire des informations vérifiables et de qualité améliore la confiance et la valeur perçue.
Créer des liens internes riches en mots‑clés : cela aide à définir le champ sémantique d’une page et à guider l’indexation.
Être concis lorsque l’on vise des modèles LLM : structurer l’information en listes et utiliser des abréviations courantes réduit la consommation de tokens.
Remarque : l’utilisation de listes structurées peut diminuer le nombre de tokens nécessaires pour représenter une information tout en améliorant la lisibilité humaine, mais selon le format et la langue, la compression peut varier.
Dernières observations
Il existe un débat autour de l’utilisation d’un format épuré (par exemple du Markdown) pour les agents : l’idée est de séparer le contenu utile du « bruit » HTML afin de faciliter l’accès des agents aux parties structurantes de la page. Une approche plus propre de l’HTML sémantique peut aussi aider à rendre le contenu plus accessible aux systèmes automatisés.
Sur le plan pratique, la clef reste de fournir une information claire, structurée et désambiguïsée. Dans un paysage saturé d’informations, privilégier la qualité sémantique et la clarté profite à la fois aux utilisateurs humains et aux systèmes automatisés.
Articles similaires
 seo
seoRéférencement local et géolocalisation : HubSpot pour les entreprises qui veulent s’imposer sur leur territoire
 seo
seoMise à jour des liens du mode IA de Google, données sur la part de clics et propagation de ChatGPT — actualité SEO
 seo
seo