L’irruption de l’IA dans l’univers de la recherche d’information remet en question plusieurs certitudes établies. Le cabinet d’analyse Ahrefs a publié, dans une étude détaillée, une comparaison approfondie entre les sources citées par des assistants basés sur l’IA et les liens affichés par les moteurs de recherche traditionnels.
Faible recoupement entre les sources citées par l’IA et les résultats des moteurs
L’analyse d’Ahrefs s’est concentrée sur le comportement de quatre assistants basés sur l’IA très utilisés : ChatGPT, Gemini, Copilot et Perplexity. L’étude, réalisée par la data scientist Xibeijia Guan, s’appuie sur un échantillon de 15 000 requêtes longues couvrant des thématiques pratiques, alimentaires, d’assurance et des requêtes multi‑lingues.
Pour chaque requête, les chercheurs ont comparé les classements affichés dans Google et Bing avec les pages citées par les assistants IA. Les références visibles dans les réponses — liens intégrés au texte ou listés en fin de réponse — ont été extraites puis mises en regard des résultats naturels des moteurs, afin de vérifier si ces pages figuraient dans le top 10 ou le top 100 des SERP.
Le constat est sans équivoque : le chevauchement reste limité. En moyenne, seulement 11 % des liens cités par les assistants se retrouvent dans le top 10 de Google ou Bing pour la même requête (précisément 10,96 %). Lorsqu’on isole Google, la proportion grimpe légèrement à 11,9 %, tandis que pour Bing elle s’établit autour de 10 %. À l’inverse, près de 80 % des références extraites des réponses des assistants n’apparaissent pas du tout dans les résultats de Google pour la formulation initiale (cf. image de une).
Quel assistant s’aligne le mieux avec les résultats de Google ?
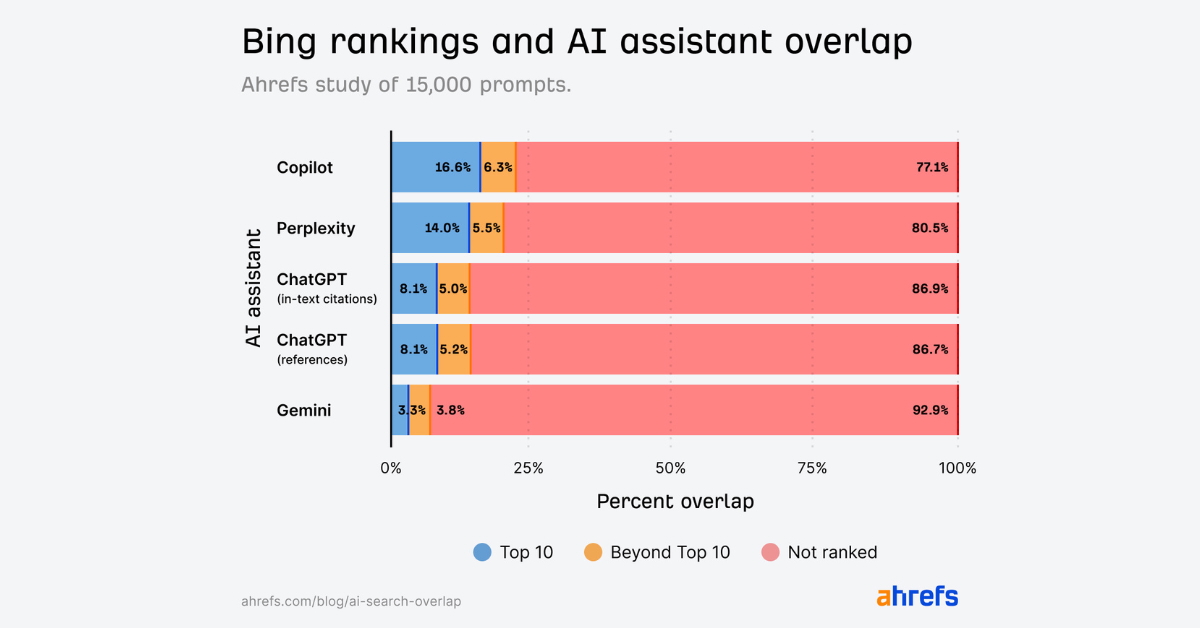
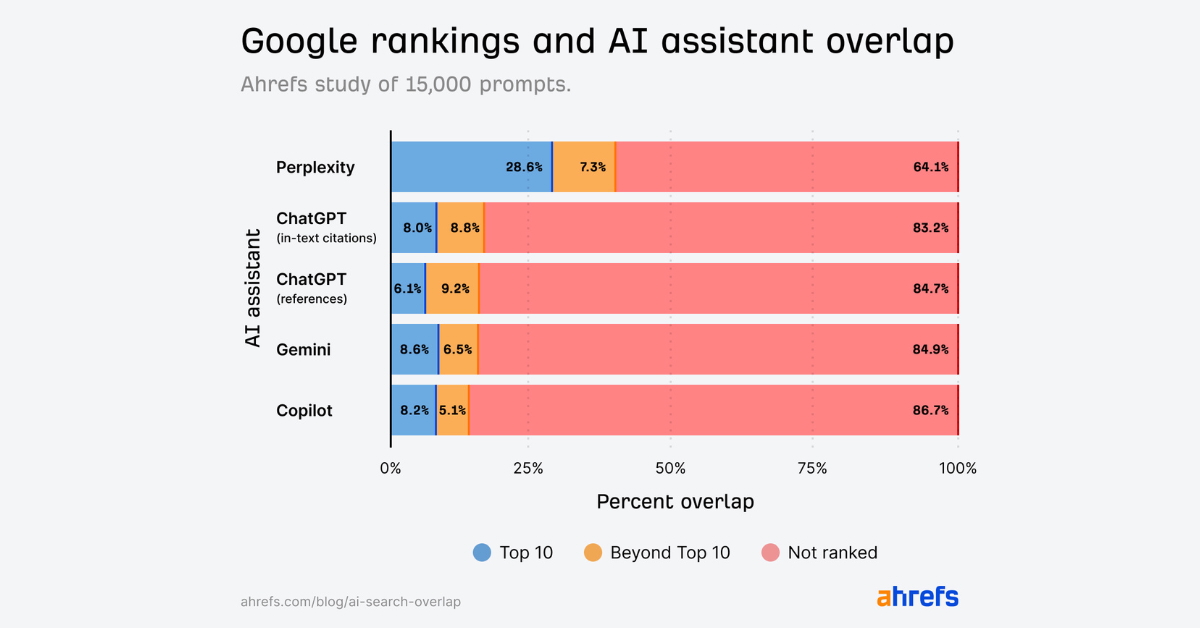
Parmi les quatre outils évalués, Perplexity émerge comme une exception notable. Présenté comme un « premier moteur de réponses », il a été conçu pour afficher systématiquement ses sources, ce qui se traduit par un meilleur alignement avec les pages bien positionnées. Selon l’étude, 28,6 % des pages citées par Perplexity figurent dans le top 10 de Google. Les autres assistants — ChatGPT, Gemini et Copilot — affichent des taux bien plus modestes, autour de 8 %.
Copilot montre un comportement particulier : il obtient un taux de recoupement plus élevé avec Bing (16,6 % dans le top 10), ce qui est cohérent avec le fait que ce produit est développé par Microsoft et s’appuie étroitement sur l’index de Bing. ChatGPT et Gemini présentent un alignement moindre, en partie parce qu’ils n’activent pas systématiquement une recherche web externe. Dans le cas de ChatGPT, l’exécution d’une requête en ligne dépend d’un mécanisme interne baptisé « sonic classifier » : si le modèle estime qu’il peut générer une réponse fiable à partir de son entraînement, il n’effectue pas de recherche externe.
Une explication technique importante pour Perplexity : contrairement à certains assistants qui interrogent directement l’index de Google ou de Bing, Perplexity s’appuie sur son propre index construit par son robot d’indexation, nommé perplexitybot. La corrélation élevée entre les références de Perplexity et les pages du top 10 de Google suggère que son index privilégie naturellement les contenus déjà bien positionnés, sans dépendre en permanence des SERP des grands moteurs.
Pourquoi les réponses des IA divergent-elles autant des SERP classiques ?
Plusieurs facteurs expliquent l’écart marqué entre les pages citées par les assistants et les résultats affichés par les moteurs de recherche. Le premier réside dans la différence de logique de sélection des sources :
- Les moteurs traditionnels répondent strictement à une requête formulée par l’utilisateur, en classant les pages selon leur pertinence pour cette formulation exacte.
- Les assistants basés sur l’IA ont souvent recours à une méthode dite de « query fan‑out » : au lieu d’exécuter la requête unique, ils génèrent une série de variantes proches (par exemple « comment détartrer une machine à café », « nettoyage machine Nespresso », « enlever calcaire cafetière ») et agrègent les résultats obtenus pour produire une réponse consolidée.
Cette agrégation peut passer par des algorithmes de fusion de classements, comme le Reciprocal Rank Fusion (RRF), qui favorise les pages apparaissant de façon récurrente dans plusieurs listes, même si elles ne figurent pas dans le top 10 pour la formulation initiale. En conséquence, une page peut être citée par un assistant IA alors qu’elle n’est pas visible dans le top 100 pour la requête exacte sur un moteur classique.
À cela s’ajoutent des éléments de personnalisation et de contexte propres aux assistants : l’historique de conversation, le ton du prompt, la langue employée ou encore des paramètres de session peuvent influer sur les sources retenues. Ainsi, deux personnes posant la même question au même assistant peuvent recevoir des listes de références différentes. Enfin, certains modèles ne cherchent pas à reproduire fidèlement les SERP : ils privilégient des critères internes (cohérence narrative, concision, sécurité) et ne vont pas nécessairement citer systématiquement des liens externes, ce qui creuse encore l’écart.
Conséquences pour le SEO et la production de contenu
Pour les responsables éditoriaux et les spécialistes du SEO, les enseignements sont concrets : un bon positionnement sur Google ou Bing ne garantit pas d’apparaître dans les références émises par les assistants IA. Optimiser uniquement pour une requête précise expose à manquer des opportunités générées par la diversité de formulations que les outils d’IA considèrent.
Les données issues de l’étude Ahrefs invitent plutôt à adopter une approche thématique plus large : travailler des clusters sémantiques, couvrir les variantes longues de requêtes et proposer des pages capables d’être utiles dans plusieurs contextes linguistiques et conversationnels. Cette stratégie augmente les chances d’être retrouvé lorsqu’un assistant combine plusieurs formulations dans sa logique de recherche élargie.
Voici des pistes d’adaptation concrètes, techniques et éditoriales :
1. Cibler les ensembles de requêtes et les thématiques (topic clusters)
Plutôt que d’optimiser une page pour une seule expression, il est préférable de concevoir des contenus couvrant un sujet dans sa globalité : questions fréquentes, variantes lexicales, expressions locales, et angles pratiques. L’objectif est de créer des pages pouvant répondre directement à des reformulations issues du query fan‑out, augmentant ainsi la probabilité d’apparaître dans des listes de référence d’assistants IA.
2. Structurer l’information pour faciliter la citation
Les assistants citent plus facilement des passages clairs, bien délimités et factuels. L’usage de sous‑titres, de paragraphes courts, d’éléments listés et de bloc‑résumé en début de page aide les modèles à extraire et à reformuler l’information. L’intégration de données structurées (schema.org) peut également améliorer la compréhension du contenu par des systèmes automatisés qui s’appuient sur des métadonnées.
3. Renforcer l’autorité et la qualité perçue
Même si l’alignement entre SERP et citations IA est imparfait, la qualité éditoriale et les signaux d’autorité restent essentiels. Des sources bien référencées, des citations externes vérifiables, une rédaction rigoureuse et des mises à jour régulières contribuent à ce que les pages soient valorisées tant par les moteurs que par certains index internes d’assistants tels que le perplexitybot.
4. Multilinguisme et adaptation contextuelle
Les assistants traitent fréquemment des requêtes dans plusieurs langues et adaptent leurs sources en fonction du contexte conversationnel. Travailler les versions multilingues d’un contenu et optimiser pour des formulations idiomatiques locales améliore la portée dans les environnements conversationnels multi‑lingues.
5. Mesurer et expérimenter
Étant donné la variabilité des résultats, il est essentiel de mettre en place des programmes d’expérimentation : monitorer les références citées par différents assistants, comparer ces sources aux positions dans les SERP, et ajuster la stratégie éditoriale en conséquence. Des métriques pertinentes incluent la visibilité dans les réponses d’IA, le trafic organique issu des pages citées, et les taux d’engagement des contenus utilisés comme référence.
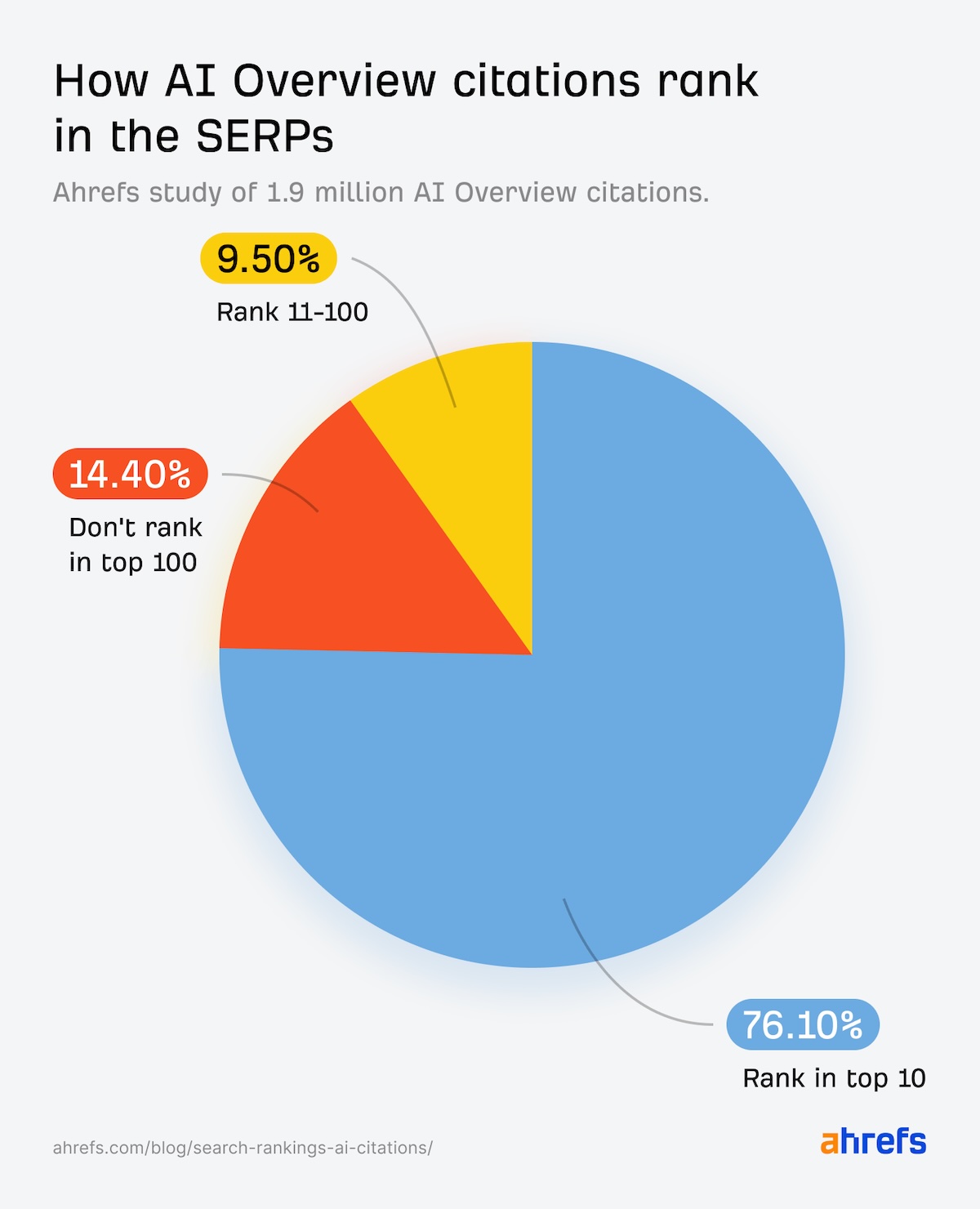
Ces adaptations ne signifient pas que l’optimisation traditionnelle pour les moteurs de recherche devient obsolète. Les SERP restent des vecteurs majeurs de trafic et de crédibilité — comme le montre le fait que les résumés d’IA de Google restent souvent alignés avec le top 10 classique — mais la cohabitation avec les assistants conversationnels impose de repenser la portée sémantique et la structure des contenus.
Limites des études et points à surveiller
Il est utile de rappeler certaines limites méthodologiques et les évolutions possibles :
- L’échantillon : l’étude porte sur 15 000 requêtes longues, ce qui est significatif, mais ne couvre pas l’ensemble des typologies de recherche (requêtes transactionnelles courtes, requêtes locales très spécifiques, recherches d’images, etc.).
- La temporalité : les comportements des modèles et des moteurs de recherche évoluent rapidement. Des mises à jour algorithmiques, des changements d’index ou des améliorations des assistants peuvent modifier la corrélation entre citations et SERP.
- Le positionnement des assistants : certains outils ont été conçus pour citer systématiquement des sources, d’autres non. Les objectifs produits (précision, concision, autonomie) influent sur la tactique de citation.
- Le risque d’« hallucination » : même si un assistant cite un lien, cela ne garantit pas la véracité ou la fiabilité du contenu référencé. La validation humaine et la vérification des sources restent nécessaires.
Que peuvent surveiller les professionnels du contenu et du SEO ?
Pour anticiper et s’adapter aux comportements des assistants basés sur l’IA, plusieurs leviers de surveillance sont recommandés :
- Créer des crawlings réguliers des réponses des assistants populaires (lorsque possible) pour extraire les pages citées et comparer ces listes aux positions dans les SERP.
- Surveiller les performances des pages multi‑thématiques et analyser si elles apparaissent plus souvent comme sources dans les réponses conversationnelles.
- Utiliser des outils d’analyse de logs et des données d’indexation pour repérer des tendances de trafic liées aux variations de formulation des requêtes.
- Mettre en place des indicateurs de qualité éditoriale (taux de rebond, durée de session, partages, taux de clic sur les extraits) afin d’évaluer la pertinence réelle des pages citées par des assistants.
Perspectives : convergence ou divergence entre IA et moteurs ?
La relation entre assistants conversationnels et moteurs de recherche pourrait évoluer de plusieurs manières :
- Convergence : si les grands acteurs (notamment Google) intègrent davantage d’outils d’IA directly dans l’expérience de recherche (AI Overviews, AI Mode, etc.), on pourrait observer un rapprochement progressif entre les pages citées par les assistants et celles du top 10. Cela dépendra des objectifs de ces fonctionnalités (montrer des sources fiables vs proposer des synthèses propriétaires).
- Divergence : si les assistants continuent d’utiliser des indexes alternatifs (comme le perplexitybot) ou de privilégier des logiques de fusion et de personnalisation, les chemins d’exposition des contenus resteront distincts des SERP classiques, créant des canaux de visibilité différents à maîtriser.
Quelle que soit l’issue, il paraît probable que la coexistence de plusieurs logiques de recherche impose aux producteurs de contenu de diversifier leurs approches : optimisation technique pour les SERP, structuration et granularité des contenus pour la consommation conversationnelle, et attention accrue à la qualité et à la vérifiabilité des informations publiées.
Ce qu’il faut retenir
La montée en puissance des assistants basés sur l’IA rend la stratégie éditoriale et SEO plus complexe, mais aussi plus riche en opportunités. L’étude d’Ahrefs montre que le simple fait d’apparaître dans le top 10 d’un moteur ne suffit plus pour garantir une exposition dans les réponses conversationnelles. Ne pas tenir compte des logiques de query fan‑out, de fusion des résultats ou du rôle d’indexes alternatifs comme le perplexitybot conduit à négliger des sources potentielles de trafic et de visibilité.
Les recommandations principales à retenir sont :
- Adopter une approche thématique (clusters) plutôt que de viser uniquement des mots‑clés isolés.
- Structurer les contenus pour qu’ils soient aisément extractibles et citables par des assistants.
- Travailler la qualité, la vérifiabilité et l’actualisation des informations afin d’augmenter la probabilité d’être retenu comme source fiable.
- Mettre en place une surveillance régulière des citations par assistants et des évolutions de la SERP.
En somme, les équipes éditoriales et SEO doivent combiner les bonnes pratiques classiques du référencement avec des démarches spécifiques visant les environnements conversationnels et multi‑index. Cette double compétence devient un levier différenciant dans un paysage où les moteurs de recherche et les assistants IA coexistent et parfois se concurrencent dans la manière d’exposer les sources d’information.
