Contrairement à Perplexity, ChatGPT se réfère rarement aux mêmes pages que Google
Ces dernières semaines, il est devenu manifeste que ChatGPT incorpore, au moins partiellement, des éléments issus de Google pour étayer …
Sommaire
- 1Requêtes courtes : Perplexity très proche de Google
- 2Même sites référencés, pas forcément les mêmes pages
- 3Que sont les fan-out queries et pourquoi elles s’écartent de Google ?
- 4Méthodologie de l’étude et limites à garder en tête
- 5Enseignements et implications pour le référencement et la création de contenu
- 6Consolider l’autorité du domaine
- 7Produire des pages complémentaires pour différentes intentions
- 8Structurer l’information pour faciliter la réutilisation
- 9Cibler les variantes de requêtes, y compris les fan-out
- 10Surveiller les citations issues des agents et adapter
- 11Fiabilité, traçabilité et enjeux éditoriaux
- 12Limitations techniques et idées pour des tests complémentaires
- 13Conclusions et perspectives pour les professionnels
- 14Questions fréquentes (FAQ)
- 15Les assistants vont-ils remplacer le trafic issu de Google ?
- 16Faut-il modifier sa stratégie SEO pour apparaître dans les réponses des IA ?
- 17Quelle différence concrète entre Perplexity et ChatGPT selon l’étude ?
- 18Articles connexes
Ces dernières semaines, il est devenu manifeste que ChatGPT incorpore, au moins partiellement, des éléments issus de Google pour étayer certaines de ses réponses. Toutefois, les systèmes conversationnels n’appliquent pas un simple copier-coller : ils effectuent ensuite des traitements propres dont la logique exacte reste difficile à décrypter. Dans une recherche publiée le mercredi 3 septembre 2025, Ahrefs a cherché à éclaircir ce fonctionnement. Les auteurs ont passé au crible plus de 3 000 requêtes variées (courtes, longues et reformulées) et ont confronté les URL citées par ChatGPT et Perplexity aux pages effectivement présentes dans les SERP de Google. Le présent article reprend les conclusions principales, les met en perspective et examine les implications pour les professionnels du référencement et de la rédaction web.
Requêtes courtes : Perplexity très proche de Google
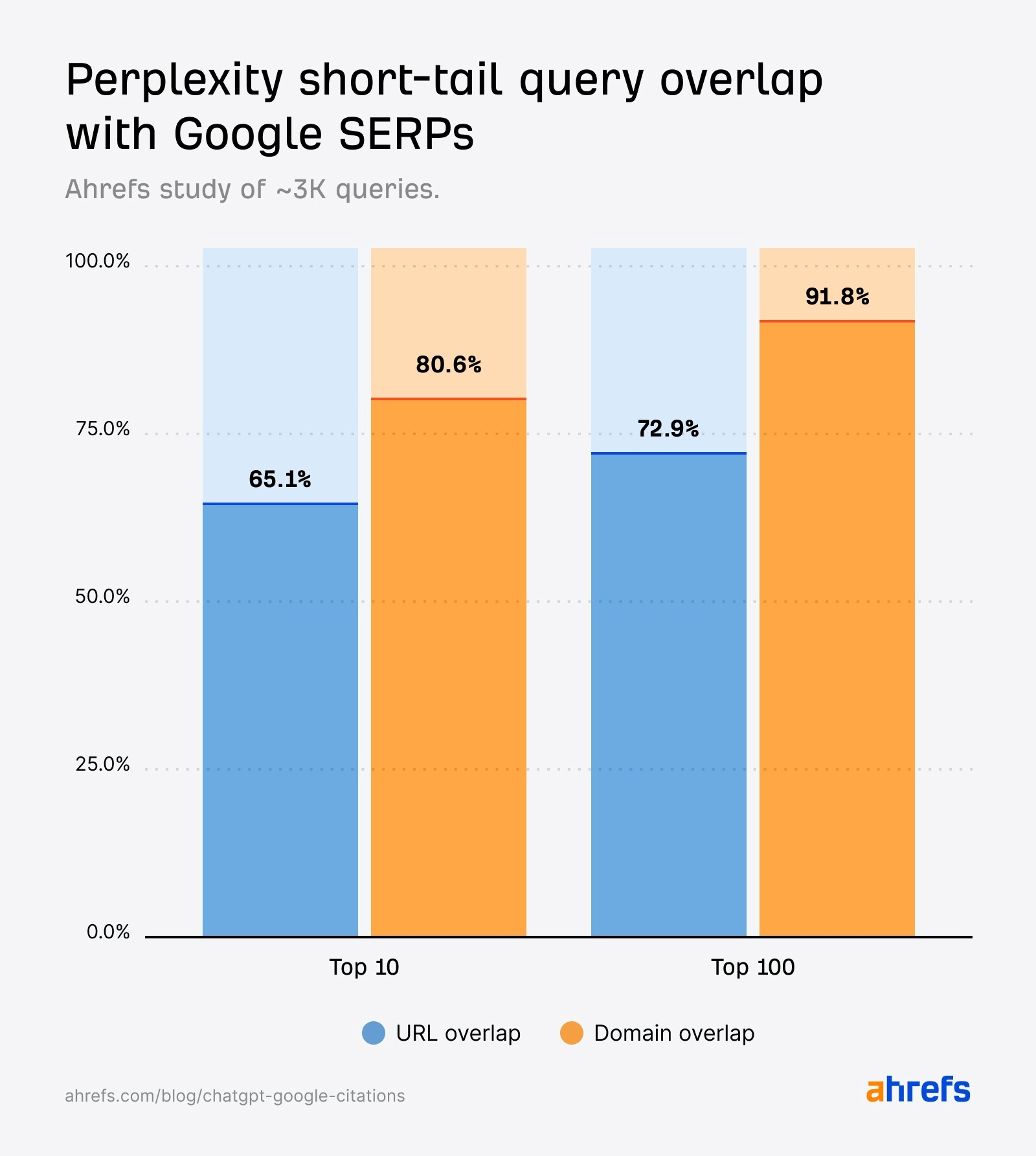
Sur les termes courts et génériques — ce que l’on désigne communément par courte traîne — l’étude d’Ahrefs montre une observation nette : « les citations de Perplexity s’alignent largement avec les résultats de recherche de Google ». Le chiffre est parlant : 65 % des URL citées par Perplexity pour des requêtes de courte traîne figurent dans le top 10 des résultats de Google.
À l’opposé, les extraits et références produits par ChatGPT pour ces mêmes requêtes courtes présentent un recouvrement nettement moindre : seulement 10 % des pages citées par ChatGPT apparaissent dans le top 10 des SERP de Google.
Les auteurs de l’étude nuancent toutefois ces chiffres : il est possible qu’un filtrage sur des requêtes « en temps réel » (actualités, sports, finance) augmenterait les similitudes, car ce sont précisément les types de requêtes pour lesquelles ChatGPT semble interroger Google, estiment-ils.
Pourquoi cette divergence entre les deux assistants ? Plusieurs éléments techniques et stratégiques peuvent l’expliquer :
- Mode d’intégration des données externes : certaines plateformes adoptent une approche « citation-first » (priorisant les sources issues des moteurs), tandis que d’autres combinent ces sources à des modèles de synthèse plus agressifs.
- Objectifs de réponse : un assistant conçu pour fournir une synthèse contextuelle pourra sélectionner et reformuler des informations issues de domaines pertinents, même si la page précise citée diffère de celle du top 10 de Google.
- Historique et indexation internes : les modèles peuvent s’appuyer sur des caches ou des index différents, parfois plus actualisés ou au contraire moins représentatifs du classement public de Google.
Même sites référencés, pas forcément les mêmes pages
L’un des enseignements importants d’Ahrefs est qu’en dépit de divergences sur les URL exactes, les deux systèmes tendent à se référer aux mêmes domaines. Autrement dit, ChatGPT et Perplexity citent souvent les mêmes sites « faisant autorité », mais pas nécessairement la même page au sein de ces domaines.
L’étude mentionne explicitement que « l’agent conversationnel cite les domaines de classement trois fois plus que les pages de classement ». Ce comportement est visible chez Perplexity également : les domaines apparaissent comme un ensemble commun, mais la granularité page-à-page diverge.
À titre d’exemple, Google peut référencer une page précise telle que ahrefs.com/writing-tools/, tandis que ChatGPT jugera qu’une section différente du même domaine (par exemple ahrefs.com/blog/) correspond mieux à la requête et la citera à la place, illustre Ahrefs.
Cette observation a des conséquences pratiques pour les stratégies de contenu et de référencement :
- La valeur d’un domaine fort : un site reconnu est susceptible d’apparaître dans des sorties d’IA même si la page citée diffère. L’autorité du domaine reste un signal puissant.
- Multiplication des angles d’entrée : il est utile de produire des contenus complémentaires qui couvrent différentes intentions, afin d’apparaître à la fois dans les SERP et comme source possible pour des modèles d’IA.
- Optimisation granulaire : au-delà d’une page phare, il faut concevoir des pages satellites répondant à variantes de requêtes (FAQ, guides, comparatifs) pour multiplier les chances d’être sélectionné par des agents qui n’alignent pas strictement leurs citations sur le top 10.
Que sont les fan-out queries et pourquoi elles s’écartent de Google ?
Les fan-out queries désignent des requêtes complexes que l’IA fractionne en plusieurs sous-requêtes parallèles pour mieux appréhender une problématique multiple ou nuancée. Plutôt que de répondre de manière directe, le modèle élabore des pistes connexes et les explore pour former une réponse plus complète.
Par exemple, une demande telle que « Peux-tu me recommander un nutritionniste spécialisé pour les sportifs à Paris ? » pourra être découpée en recherches dérivées : « meilleurs nutritionnistes pour sportifs à Paris », « avis clients nutritionnistes sportifs », « tarifs consultations nutrition sport Paris », etc. Ce processus « en éventail » permet d’obtenir une vision multi-dimensionnelle du sujet.
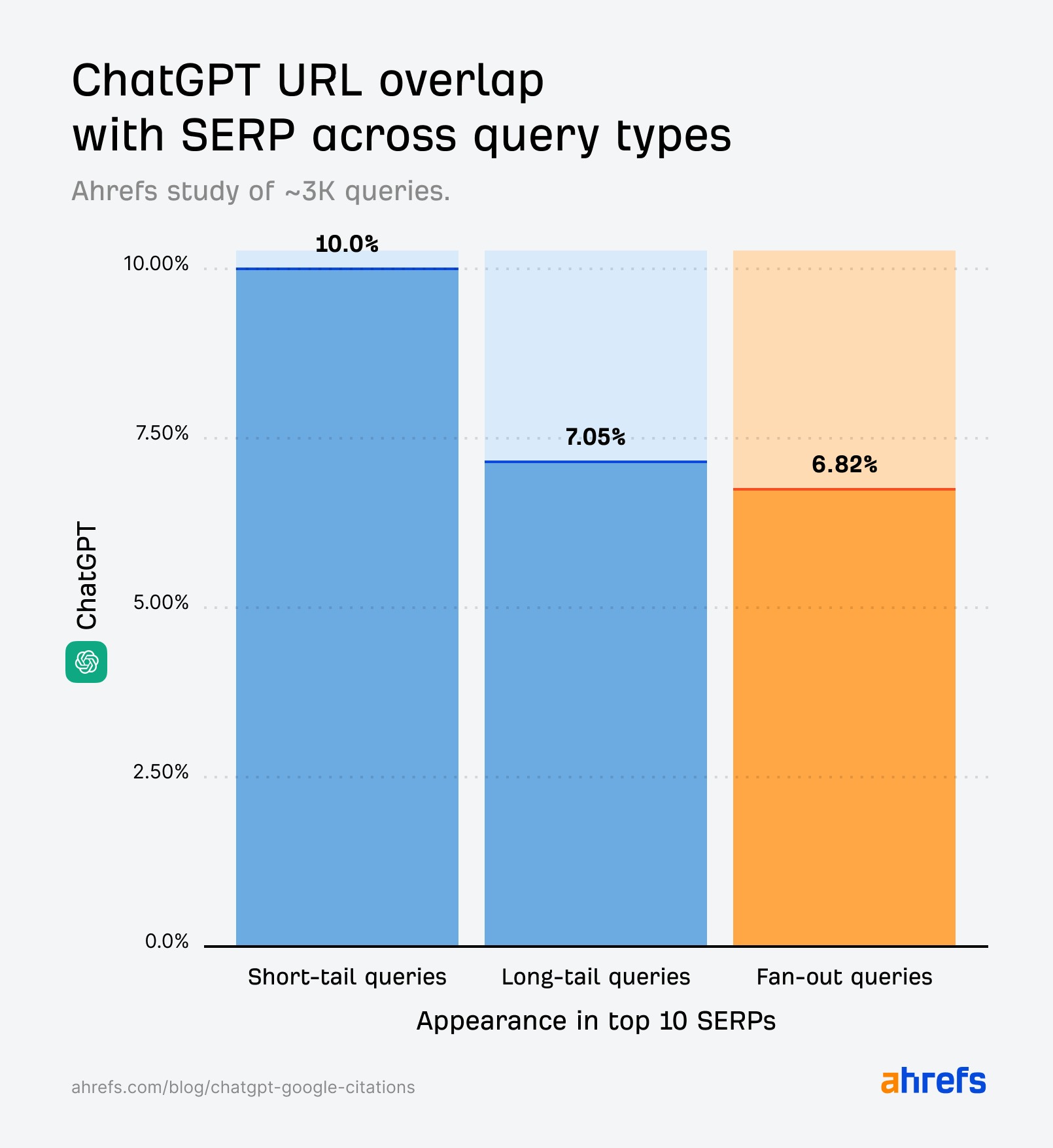
Or, selon Ahrefs, ce comportement induit un plus faible chevauchement avec les SERP classiques de Google. Les chiffres parlent d’eux-mêmes : seules 6,82 % des pages citées par ChatGPT pour des fan-out queries apparaissent dans le top 10 de Google. C’est un taux inférieur à celui observé pour les requêtes longues (7,05 %) et pour les courtes (10 %).
En comparaison, Perplexity maintient un taux de recouvrement plus élevé, ce qui corrobore le schéma global de l’étude : Perplexity adopte une logique plus fidèle aux résultats du moteur, tandis que ChatGPT reconstruit et recombine l’information selon une approche de synthèse.
Méthodologie de l’étude et limites à garder en tête
Avant d’extrapoler les résultats, il convient de rappeler certains éléments méthodologiques et limites étayés par l’équipe d’Ahrefs :
- Échantillon : plus de 3 000 requêtes ont été analysées, ce qui offre une base solide mais pas exhaustive de tous les cas d’usage possibles.
- Typologie des requêtes : l’étude a distingué entre requêtes courtes, longues et fan-out, mais d’autres catégories (locales, transactionnelles, info temps réel) peuvent produire des dynamiques différentes.
- Temporalité : les SERP évoluent continuellement. Des changements d’indexation ou d’algorithme côté Google peuvent modifier les chevauchements au fil du temps.
- Mécanismes propriétaires : les méthodes exactes par lesquelles ChatGPT et Perplexity intègrent, pondèrent et citent les sources restent en partie opaques, car elles relèvent de technologies et d’implémentations propriétaires.
En résumé, si les tendances dégagées par l’étude sont robustes, elles ne signifient pas qu’un assistant X ou Y produira systématiquement les mêmes résultats pour toutes les requêtes. Ces chiffres sont des indicateurs utiles mais non absolus.
Enseignements et implications pour le référencement et la création de contenu
Pour les responsables SEO, les créateurs de contenu et les éditeurs, les observations d’Ahrefs ouvrent plusieurs pistes opérationnelles :
Consolider l’autorité du domaine
Le fait que les deux agents citent fréquemment les mêmes domaines montre l’importance durable de l’autorité de domaine. Travailler à renforcer la réputation globale d’un site — qualité éditoriale, backlinks pertinents, expérience utilisateur fiable — reste un levier majeur pour apparaître en tant que source citée par des assistants.
Produire des pages complémentaires pour différentes intentions
Plutôt que d’espérer que la « page principale » monopolise toutes les citations, il est préférable de déployer une architecture de contenus en silo : articles détaillés, pages FAQ, guides pratiques, études de cas et pages locales. Cette stratégie augmente les probabilités d’être sélectionné par une IA qui privilégie une page différente du top 10 de Google.
Structurer l’information pour faciliter la réutilisation
Les assistants tirent avantage de contenus structurés et explicites. Employer des balises sémantiques, des données structurées (schema.org), des titres clairs et des résumés bien formatés facilite l’extraction d’informations pertinentes par des processus automatiques. Les extraits bien organisés sont plus facilement repris et cités.
Cibler les variantes de requêtes, y compris les fan-out
Étant donné la propension de ChatGPT à fragmenter certaines demandes, il est judicieux de couvrir les variantes et sous-thèmes qui émergent naturellement d’une thématique. Par exemple, pour un sujet « nutrition sportive », publier des contenus distincts sur les tarifs, les avis, l’expertise, les spécialisations, etc., augmente la visibilité dans des sorties d’IA multi-pistes.
Surveiller les citations issues des agents et adapter
Intégrer un suivi régulier des mentions et des citations apportées par les assistants (lorsque ces données sont accessibles) permet d’identifier quelles pages sont reprises et pour quelles intentions. Cette veille aide à ajuster le maillage interne et la profondeur des contenus.
Fiabilité, traçabilité et enjeux éditoriaux
L’étude d’Ahrefs rappelle aussi des questions non seulement techniques mais éditoriales et éthiques :
- Transparence des sources : lorsque ChatGPT reformule fortement une information, il est plus difficile pour l’utilisateur final de vérifier l’origine exacte des éléments cités.
- Risque d’erreurs de synthèse : en recomposant des passages, un modèle peut involontairement introduire des imprécisions ou des amalgames qui n’apparaîtraient pas si la source était citée mot pour mot.
- Responsabilité de l’éditeur : pour les sites d’autorité, apparaître comme source dans une réponse d’IA peut renforcer la visibilité mais implique aussi de garantir l’exactitude et la mise à jour des contenus référencés.
Ces aspects incitent à maintenir des standards éditoriaux élevés : citations claires dans les contenus, mises à jour régulières, sources vérifiables et pages de référence bien documentées.
Limitations techniques et idées pour des tests complémentaires
Plusieurs axes restent à explorer pour compléter les résultats d’Ahrefs :
- Segmenter les tests par verticales : santé, finance, juridique, e-commerce et actualités peuvent présenter des comportements distincts en termes de recouvrement.
- Tester la temporalité : comparer les résultats selon la fraîcheur des données (requêtes « en temps réel » vs requêtes intemporelles).
- Évaluer l’effet des prompts : analyser si et comment des formulations de questions différentes influencent la sélection des sources par l’IA.
- Comparer d’autres assistants : étendre l’échantillon à d’autres agents conversationnels pourrait confirmer si les tendances observées sont générales ou propres aux solutions examinées.
Conclusions et perspectives pour les professionnels
La synthèse proposée par l’étude d’Ahrefs dégage un panorama utile : Perplexity tend à refléter de façon plus fidèle les SERP de Google, surtout sur les requêtes de courte traîne, tandis que ChatGPT opte parfois pour une recomposition plus autonome des résultats, en particulier lors de requêtes complexes ou fragmentées (fan-out).
Pour les acteurs du web, cela signifie qu’il existe plusieurs chemins pour apparaître dans l’écosystème des assistants :
- Travailler l’autorité du domaine pour rester visible dans les deux approches.
- Multiplier les contenus ciblés pour répondre aux différentes intentions et augmenter les chances d’être cité, que l’assistant reprenne une page précise ou une page satellite.
- Soigner la structure et la qualité des pages afin de faciliter l’extraction d’informations par des systèmes automatiques.
Enfin, la coexistence de ces modèles souligne que le paysage de l’information s’enrichit mais se complexifie : la relation entre moteurs traditionnels et assistants conversationnels est en évolution et mérite une observation continue.
Questions fréquentes (FAQ)
Les assistants vont-ils remplacer le trafic issu de Google ?
Il est prématuré d’affirmer un remplacement complet. Les assistants et les SERP servent souvent des usages différents : les moteurs favorisent la découverte et la navigation, tandis que les assistants proposent des synthèses rapides et conversationnelles. Les deux canaux peuvent coexister et se compléter.
Faut-il modifier sa stratégie SEO pour apparaître dans les réponses des IA ?
Au-delà des fondamentaux du SEO (contenu de qualité, backlinks, performance technique), il est pertinent d’optimiser la structure du contenu, d’ajouter des résumés clairs et des données structurées, et de couvrir des variations d’intentions — autant d’éléments qui peuvent faciliter la réutilisation par les assistants.
Quelle différence concrète entre Perplexity et ChatGPT selon l’étude ?
L’étude d’Ahrefs montre que Perplexity fournit des citations qui correspondent davantage au top 10 de Google, surtout pour les requêtes courtes, tandis que ChatGPT tend à reconstruire ou recomposer des réponses à partir de sources variées, ce qui peut diminuer le chevauchement avec les SERP.
Services associés
Articles similaires
 seo
seoMise à jour des liens du mode IA de Google, données sur la part de clics et propagation de ChatGPT — actualité SEO
 seo
seoJouez pour gagner un exemplaire de « SEO sans migraine », premier ouvrage d’Amandine Bart
 seo
seo