OpenAI a publié jusqu’ici la plus vaste étude sur les usages réels de ChatGPT. J’ai condensé et synthétisé les conclusions les plus utiles pour nous — celles qu’il vaut la peine de connaître — afin que vous n’ayez pas à parcourir une masse d’observations, parfois pertinentes, parfois accessoires.
En bref
- Les LLMs ne remplacent pas directement la recherche traditionnelle. En revanche, ils modifient la manière dont les gens accèdent et consomment l’information.
- Les requêtes de type Asking (interrogation) (49 %) et Doing (exécution/génération) (40 %) sont prédominantes et s’améliorent en qualité.
- Les trois usages principaux — **Conseils pratiques**, **Recherche d’informations** et **Rédaction** — représentent environ **80 %** des échanges humains–machine.
- Pour les **éditeurs** et producteurs de contenu, il devient essentiel de créer des ressources « linkables » et à forte valeur ajoutée. Il ne suffit plus de produire des articles dans l’espoir d’attirer uniquement du trafic.
 Image Credit: Harry Clarkson-Bennett
Image Credit: Harry Clarkson-BennettPrincipes fondamentaux d’un chatbot
Un **chatbot** moderne est essentiellement un modèle statistique conçu pour générer une réponse textuelle à partir d’une saisie textuelle. En termes simples : il apprend à imiter des patterns linguistiques observés dans de grandes quantités de données.
Les modèles les plus élaborés suivent au moins deux phases d’apprentissage. Lors de la phase initiale (souvent désignée par « pré-entraînement »), les LLMs sont entraînés à prédire le mot suivant dans une séquence. C’est une tâche incroyablement efficace pour capter la structure du langage et les relations sémantiques de base.
Dans cette première étape, ils deviennent extrêmement prévisibles — ce qui n’est pas forcément négatif. Pour certaines applications, la prévisibilité et la stabilité sont des qualités souhaitables (par exemple pour du code ou des formulations juridiques).
La deuxième phase, appelée souvent « post‑entraînement » ou « affinage », vise à améliorer la qualité des réponses. Les modèles sont ajustés avec des techniques comme l’apprentissage par renforcement à partir de feedback humain (RLHF) ou d’autres stratégies pour favoriser des sorties plus utiles, sûres et pertinentes.
Au fil de cette étape, les modèles sont récompensés ou pénalisés en fonction de la qualité de leurs réponses — un peu comme on entraîne un animal à associer une action à une conséquence.
Lors de la première phase, le modèle acquiert une représentation latente du monde ; lors de la seconde, cette connaissance est raffinée afin de produire des réponses de meilleure qualité.
Un paramètre important que l’on rencontre souvent est la température. Sans variation de température, un modèle deterministe produira la même sortie pour la même entrée si le reste du processus est identique.
Des températures élevées (proches de 1.0) augmentent l’aléa et la créativité des réponses. Des températures basses (proches de 0) rendent la génération plus déterministe et précise. Selon le but recherché, on ajustera donc ce paramètre : pour de la correction de code on privilégiera des températures basses ; pour de la création littéraire, des températures plus élevées peuvent être bénéfiques.
J’ai déjà évoqué ce sujet dans un contenu sur la construction d’une marque après l’arrivée de l’IA. Pour une explication technique et pratique de la température, ce guide est utile : guide sur l’échelle de température des LLMs.
Que nous apprennent les données ?
Globalement, les éléments disponibles indiquent que les LLMs ne constituent pas une substitution directe aux moteurs de recherche traditionnels. À mon sens, ils restent complémentaires. Par exemple, une analyse de Semrush montre que les utilisateurs intensifs de modèles conversationnels ont même accru leur recours aux recherches classiques — un phénomène qu’on peut appeler théorie d’expansion d’usage.
Mais il est incontestable que l’arrivée des interfaces conversationnelles transforme la façon dont les personnes interagissent avec l’information, en particulier dans un contexte professionnel : elles permettent d’obtenir des réponses synthétiques, des étapes concrètes, ou des reformulations sans quitter le flux de travail.
Autrement dit : l’accès à l’information devient plus immédiat, pragmatique et souvent intégré aux outils de travail.
1. Les usages dominants : conseils pratiques, recherche d’informations et rédaction
Les trois catégories d’interaction les plus fréquentes représentent environ **80 %** des conversations. Cela inclut les demandes de **guidance pratique** (comment faire quelque chose), les requêtes d’**information** et les tâches de **rédaction**. Ces usages révèlent une adoption très tournée vers l’utilité instantanée et la résolution de problèmes concrets.
Dans la pratique, une large part des requêtes de **rédaction** concernent la révision ou l’amélioration d’un texte existant plutôt que la production d’un contenu totalement nouveau. Pour beaucoup d’utilisateurs, l’intérêt principal est d’obtenir une version plus claire, plus concise ou mieux structurée d’un document déjà amorcé.
Sur le plan éthique et éditorial, il y a aussi un ressenti de malaise : certains lecteurs ou créateurs se sentent trompés si un texte qui paraît humain est en réalité produit par un modèle. La transparence et l’authenticité restent des enjeux importants.
2. Usage hors travail en forte hausse
- Les messages à finalité non professionnelle sont passés d’environ 53 % à **plus de 70 %** à la date de l’étude (juillet 2025).
- Les LLMs s’inscrivent désormais dans des habitudes quotidiennes : aide à la prise de décision, préparation de messages personnels, planification, etc., tant au bureau qu’en dehors.
3. La rédaction reste l’usage le plus répandu en entreprise
- Au travail, la **rédaction** représente la part la plus importante d’utilisation, soit environ **40 %** des messages liés au milieu professionnel (moyenne en juin 2025).
- Environ **les deux tiers** des demandes de rédaction visent à modifier ou améliorer du texte fourni par l’utilisateur plutôt qu’à créer un contenu inédit.
Je connais de nombreuses personnes qui utilisent les modèles avant tout pour polir leurs e‑mails. C’est révélateur de la nature utilitariste de ces outils dans les usages professionnels courants.
4. La programmation n’est pas l’usage principal
- Les requêtes liées à la **programmation** représentent une faible part des échanges : seulement **4,2 %** de l’ensemble des messages dans cette étude.
- Cela peut paraître surprenant : des solutions spécialisées comme Claude ou des outils ciblés tels que Lovable sont souvent plus adaptées pour des tâches de codage poussées.
- Cela montre que les **LLMs spécialisés** — entraînés et affinés pour des domaines précis — vont probablement gagner en importance dans des secteurs spécifiques car ils fournissent des sorties de meilleure qualité pour leurs cas d’usage dédiés.
*À titre de comparaison, une partie des échanges liés au travail sur Claude représenterait environ 33 % pour des usages similaires selon une autre source citée.*
Il est important de rappeler que différentes études peuvent aboutir à des conclusions divergentes sur les usages. Les chiffres changent au fil du temps et selon l’échantillon observé.
5. Évolution démographique : la domination masculine s’atténue
- Aux débuts de l’adoption, les utilisateurs étaient majoritairement masculins (environ **80 %** avec des noms typiquement masculins dans les enregistrements initiaux).
- Ce taux est retombé à **48 %** en juin 2025 : la base d’utilisateurs actifs est désormais plus équilibrée en termes de genre.
Cette évolution reflète une phase de démocratisation de l’accès : les outils sortent d’un cercle d’initiés pour toucher des publics plus variés.
- Environ **89 %** de toutes les requêtes appartiennent aux catégories **Asking** et **Doing**.
- Répartition : **49 %** pour Asking, **40 %** pour Doing, et seulement **11 %** pour Expressing (expression personnelle/créative).
- Sur l’année observée, les messages de type Asking ont crû plus rapidement que ceux de type Doing, et ils sont généralement jugés de meilleure qualité.
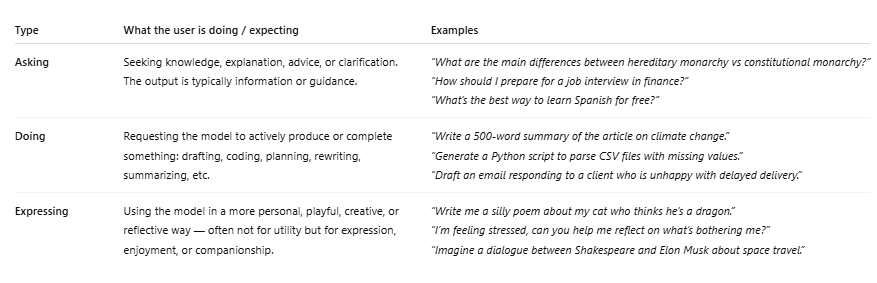 Tableau généré par ChatGPT avec des exemples pour chaque type de requête — Asking, Doing, et Expressing (Image Credit: Harry Clarkson-Bennett)
Tableau généré par ChatGPT avec des exemples pour chaque type de requête — Asking, Doing, et Expressing (Image Credit: Harry Clarkson-Bennett)6. Les relations personnelles et la réflexion intime restent minoritaires
- Plusieurs études ont évoqué l’idée selon laquelle les LLMs pourraient jouer un rôle de support émotionnel ou quasi-thérapeutique.
- Pourtant, selon les données d’OpenAI, les sujets liés aux relations et à la réflexion personnelle ne représentent que **1,9 %** des messages totaux.
7. Les jeunes ? Une population davantage consommatrice
Les publics plus jeunes semblent adopter plus rapidement ces interfaces conversationnelles, à la fois parce qu’ils les trouvent intuitives et parce qu’ils leur font davantage confiance pour des tâches quotidiennes. Cela a des implications marketing et éditoriales : les audiences jeunes peuvent être plus enclines à accepter des réponses synthétiques, à tester des outils, et à intégrer ces systèmes dans leurs routines.
Conséquences pratiques pour les éditeurs et le SEO
Les résultats n’annoncent pas la fin du SEO pour les éditeurs. En revanche, ils appellent à repenser les priorités : au lieu de viser uniquement le trafic via des articles d’actualité ou des listes de conseils génériques, il devient nécessaire de développer des actifs numériques qui apportent une valeur difficilement réplicable par un modèle.
Quelques orientations concrètes :
- Favoriser les contenus et outils que l’on peut qualifier de « linkables » : bases de données, calculateurs, visualisations interactives, guides méthodiques avec données originales, études, et ressources exclusives. Ces éléments génèrent des liens entrants et du trafic qualifié, souvent durable.
- Mettre en avant des opinions d’experts et des analyses signées : des interviews approfondies, des enquêtes terrain, des enquêtes à valeur ajoutée non synthétisable facilement par un modèle (données propriétaires, enseignements terrain, commentaires d’experts).
- Développer des outils répondant aux requêtes de type Doing : générateurs de modèles, convertisseurs, assistants interactifs, ou micro‑services qui résolvent un problème spécifique de l’utilisateur de manière répétée.
- Ne pas abandonner la rigueur éditoriale : vérifier les faits, documenter les sources et conserver des standards élevés de vérification, car les modèles peuvent produire des réponses plausibles mais inexactes.
- Sur le plan technique, soigner l’architecture : données structurées (schema.org), API publiques pour les outils, pages rapides et accessibles, et signaux de qualité (auteurs identifiés, provenance des données, transparence sur la méthodologie).
 Trafic de faible qualité et en petit volume (Image Credit: Harry Clarkson-Bennett)
Trafic de faible qualité et en petit volume (Image Credit: Harry Clarkson-Bennett)La montée des requêtes **Doing** change également la nature des opportunités : plutôt que de viser uniquement une position dans les résultats, il faut fournir des réponses exploitables directement — petits outils embarqués, templates, ou modules interactifs qui se prêtent à une réutilisation régulière.
Autre point : la suppression progressive de certaines citations dans les réponses publiques des modèles (sauf pour les utilisateurs payants) a réduit les volumes de trafic référent direct pour certains éditeurs. Cela complexifie la mesure de l’impact réel de ces interfaces sur les audiences et oblige à diversifier les sources de monétisation et d’acquisition.
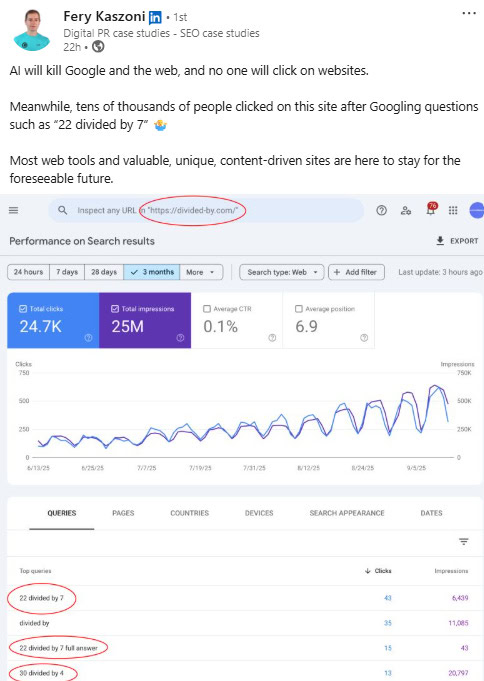 Même des outils simples peuvent générer du trafic et du revenu importants (Image Credit: Harry Clarkson-Bennett)
Même des outils simples peuvent générer du trafic et du revenu importants (Image Credit: Harry Clarkson-Bennett)Stratégies tactiques recommandées
Voici des actions concrètes que les équipes éditoriales et SEO peuvent envisager pour s’adapter à la réalité des interfaces conversationnelles :
- Inventorier les contenus existants et identifier ceux qui peuvent être transformés en outils ou en guides approfondis : checklists interactives, calculateurs, infographies enrichies, jeux de données accessibles via API.
- Prioriser les sujets « Doing » pour lesquels un utilisateur revient régulièrement (modèles de documents, scripts, snippets, générateurs). Ces actifs créent une valeur récurrente et une fidélité d’usage.
- Améliorer la qualité de l’information : documentation transparente, auteurs identifiés, méthodologie, citations vérifiables — autant d’atouts pour être perçu comme source fiable par les humains et par les systèmes automatisés.
- Structurer le contenu pour qu’il soit facilement interprétable par des modèles et moteurs : titres clairs, résumés, sections Q&A, listes, schémas et données structurées (JSON‑LD).
- Tester des formats interactifs et mesurer le temps d’utilisation, les retours utilisateurs et la rétention — les outils qui répondent à un besoin concret gardent les visiteurs plus longtemps.
- Surveiller la provenance du trafic et la façon dont les réponses des modèles affectent les comportements : remonter les signes de désinformation, erreurs fréquentes ou détournements de contenu.
Points de vigilance et enjeux
Plusieurs éléments méritent attention :
- Qualité vs. Quantité : produire du volume ne suffit plus ; la valeur ajoutée originale devient un avantage compétitif.
- Risques de duplication : les modèles peuvent regurgiter des phrasing et des synthèses proches de contenus existants. Garder des sources uniques et des angles exclusifs protège contre l’érosion éditoriale.
- Éthique et transparence : indiquer quand du contenu a été assisté par un modèle et expliquer la méthodologie ou les sources utilisées.
- Spécialisation : les modèles de niche, entraînés sur des corpus spécialisés, offriront de meilleurs résultats dans des domaines techniques ou réglementés (santé, juridique, finance).
- Comportement de crawling : certains acteurs montrent des pratiques agressives de collecte et d’indexation ; cela peut poser des problèmes de charge serveur et d’utilisation non autorisée de contenu.
Conclusions et points d’action
Les LLMs ne ruinent pas automatiquement les modèles éditoriaux existants, mais ils redéfinissent la manière dont l’information est demandée et utilisée. Pour les éditeurs, la clé consiste à créer des ressources qui vont au‑delà de la simple présentation d’informations : outils, données, analyses d’experts et contenus difficilement synthétisables par des modèles non spécialisés.
Il reste une course pour produire des actifs numériques de qualité qui restent utiles même si un utilisateur dispose d’un modèle conversationnel dans sa boîte à outils. Les organisations qui possèdent un public engagé, une expertise identifiée et des ressources propriétaires ont de bonnes chances de tirer leur épingle du jeu.
Enfin, il faut garder à l’esprit que l’écosystème évolue rapidement : les usages et la qualité des modèles continueront de changer, et les stratégies éditoriales et techniques devront s’adapter de façon itérative.
Ressources complémentaires :
- Article original sur Leadership in SEO (version source).
- Analyse comparative sur les habitudes de recherche après l’adoption de ChatGPT : Semrush.
Post initialement publié sur Leadership in SEO.
Image à la une : Roman Samborskyi/Shutterstock
