Comment évaluer les performances sur Google Discover
En bref Pour tirer le meilleur parti de Discover, il faut l’aborder comme une plate-forme axée sur les entités : …
Sommaire
- 1Principes essentiels de Discover
- 2Quelles données analyser en priorité ?
- aCTR : pilier des contenus en temps réel
- bAnalyse des entités
- cSous‑dossiers et architecture
- dAuteur et signalement de la paternité
- eTypes de titres et catégorisation
- fImages : rôle et catégorisation
- gPerformance de publication
- 3Comment articuler ces analyses en pratique ?
- aArticles connexes
En bref
- Pour tirer le meilleur parti de Discover, il faut l’aborder comme une plate-forme axée sur les entités : personnes, lieux, organisations, équipes, etc.
- La probabilité de succès d’un article isolé dans Discover augmente si cet article dépasse ses performances prévues dès ses premières heures. Le partage et la visibilité initiale sont déterminants.
- Ensuite, il convient d’analyser la nature de vos contenus : qu’est‑ce qui génère des clics ? Qu’est‑ce qui trouve un écho ? Quelles combinaisons titre/image fonctionnent le mieux ?
- Un CTR élevé est essentiel, mais des titres dits de curiosity gap qui déçoivent pénalisent la crédibilité sur le long terme. La satisfaction utilisateur prime sur la simple recherche de clics.
Discover n’est pas une boîte noire totale. Grâce à une analyse méthodique, on peut reconstituer son fonctionnement et en extraire davantage de valeur sans sacrifier la qualité éditoriale.
Il restera toujours un peu d’inattendu. Mais on peut optimiser l’usage de la plate‑forme sans recourir à des pratiques sensationnalistes du type :
« Survivez à vos enfants grâce à cette astuce secrète que le gouvernement vous cache. »
Principes essentiels de Discover
Avant de se lancer, il est utile de vérifier la profondeur du bain.
« Une présence régulière dans la recherche aide à maintenir votre statut d’éditeur digne de confiance. »
- Discover privilégie le contenu récent. Les contenus evergreen peuvent apparaître, mais ils sont en général très corrélés à l’actualité.
- Les formats plus orientés lifestyle et engageants ont tendance à mieux fonctionner sur cette interface sans clics initiaux apparents.
- Comme pour l’actualité, Discover est fortement dépendant des entités, du CTR, et de l’engagement précoce.
- La personnalisation regroupe des cohortes d’utilisateurs : si vous répondez aux attentes d’un de ces groupes, d’autres membres du même groupe sont susceptibles d’être atteints.
- Si un contenu surperforme ses estimations lors de la phase initiale, il a plus de chances d’être mis en avant.
- Une fois que les groupes d’utilisateurs potentiellement intéressés sont saturés, la visibilité baisse naturellement.
- Google facilite la découverte de créateurs individuels et de contenus vidéo sur la plate‑forme, car les utilisateurs font souvent davantage confiance aux personnes et aux formats vidéo.
Il existe évidemment des pratiques destinées à « jouer » l’algorithme, et certaines sociétés en ont tiré profit à grande échelle. Pour un aperçu des problèmes de spam, on peut consulter cet état des lieux.
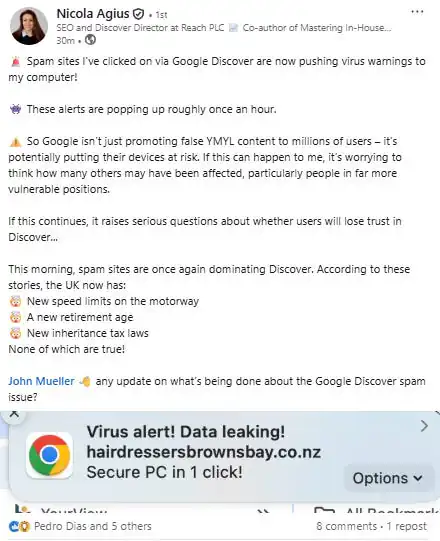
La plupart des algorithmes suivent la règle de la « Golden Hour ». Cela signifie que la première heure après la publication conditionne fortement l’amplification ou l’enterrement du contenu.
Pour espérer une forte diffusion, il faut donc générer de l’engagement dès le début.
Quelles données analyser en priorité ?
Cette section s’adresse surtout aux spécialistes SEO et aux analystes qui cherchent à maximiser la valeur de Discover. En partant du principe que vous mesurez déjà les conversions et les clics/impressions au sens classique, voici les éléments à approfondir.
Les indicateurs suivants permettent d’aller au‑delà du superficiel :
- CTR.
- Entités (personnes, lieux, organisations).
- Sous‑dossiers (structure des URLs, rubriques).
- Auteur et signalement de la paternité des contenus.
- Titres et images.
- Type de contenu (actualité, tutoriel, interview, guide evergreen, etc.).
- Performance de publication (jours, heures, fréquence, fraîcheur).
Si vous ne recevez pas encore de trafic depuis Discover, cette démarche ne produira pas immédiatement d’insights exploitables : il faut d’abord acquérir un trafic initial. À défaut, commencez par produire un contenu original et qualitatif dans vos thématiques pour bâtir cette base.
Analyser ces paramètres permet de comprendre non seulement ce qui attire les utilisateurs, mais aussi ce qui les retient.
Il est important de savoir que l’identification précise du trafic provenant de Discover dans les outils d’analyse est imparfaite. Beaucoup d’organisations se livrent à une estimation raisonnée, en combinant des signaux Google et des indicateurs mobiles/Android.
CTR : pilier des contenus en temps réel
Le CTR est une métrique centrale dans le SEO orienté actualité : Top Stories, Discover, et toute forme de SEO en temps réel la placent au cœur des décisions algorithmiques. L’algorithme détermine presque en temps réel si un contenu mérite d’être amplifié, contrairement au référencement evergreen qui évolue sur des périodes plus longues.
Le CTR est souvent pondéré par des signaux d’engagement plus traditionnels (clics, interactions sur la page, durée de session) que certains outils regroupent sous des appellations comme Navboost.
C’est aussi une des raisons pour lesquelles le clickbait perd progressivement de son efficacité : les utilisateurs finissent par se lasser et réagir négativement aux titres trompeurs ou aux contenus peu qualitatifs.
Pour exploiter au mieux le CTR, il faut l’analyser en corrélation avec :
- Le type d’images.
- Le type de titres (et le format du contenu).
- L’analyse des entités.
Analyse des entités
Les entités sont particulièrement déterminantes dans le domaine de l’actualité. Le SEO centré sur les entités existe depuis plusieurs années, mais les sites d’information ont toujours fonctionné implicitement autour de ces référents (personnes, lieux, organisations).
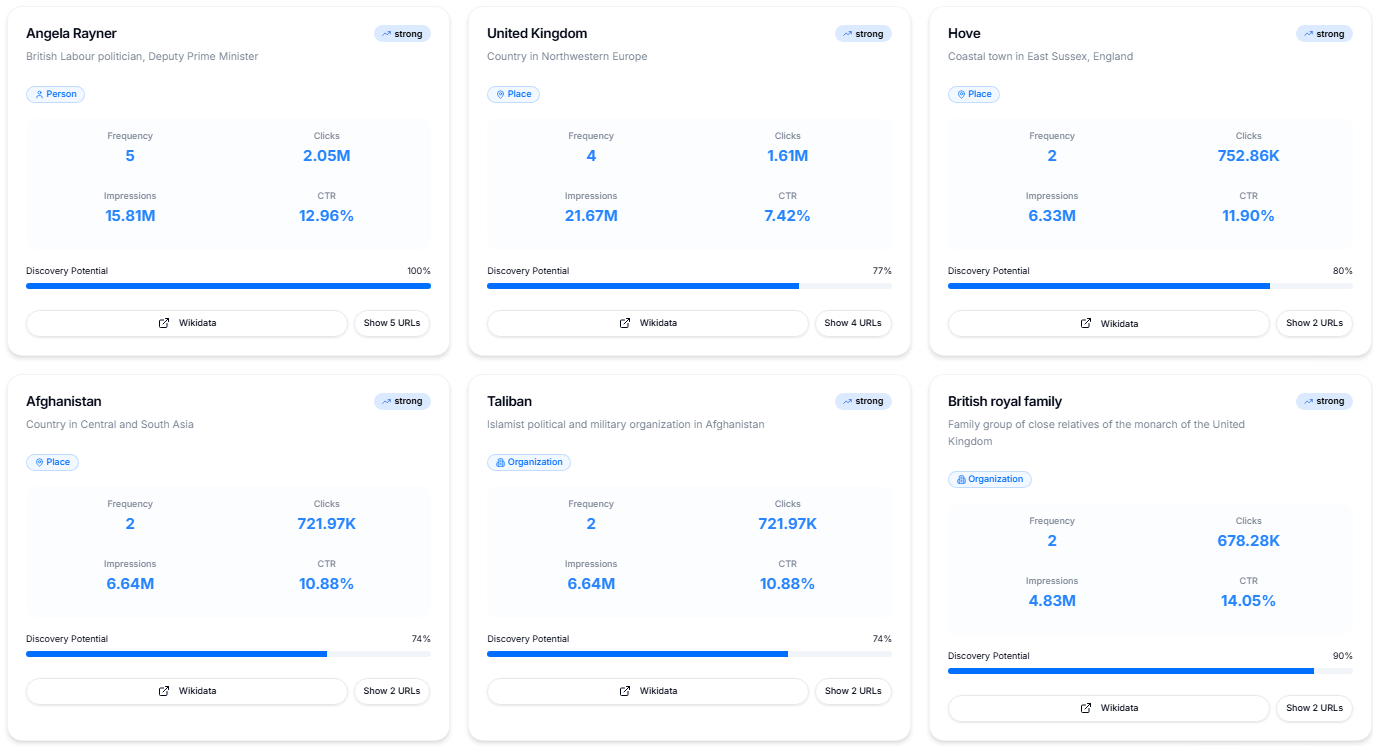
Il n’est plus suffisant de simplement « fourrer » des noms d’entités dans les titres ; néanmoins, étudier la performance à ce niveau reste très précieux, notamment pour Discover.
L’enjeu est d’identifier quelles personnes, quels lieux et quelles organisations (ces trois catégories représentent souvent plus de 85 % des entités pertinentes) apportent le plus de valeur et d’engagement sur la plate‑forme.
La véritable analyse d’entités ne peut pas se faire manuellement à grande échelle. Il est préférable d’associer un modèle de langage, un outil de NER (Named Entity Recognition) et une source de désambiguïsation comme le Knowledge Graph ou WikiData.
Avec cette approche, on peut extraire l’entité du titre, la désambiguïser via le contenu de la page (pour savoir si « Apple » renvoie à la marque, au fruit ou à autre chose), puis la confirmer dans WikiData ou le Knowledge Graph.
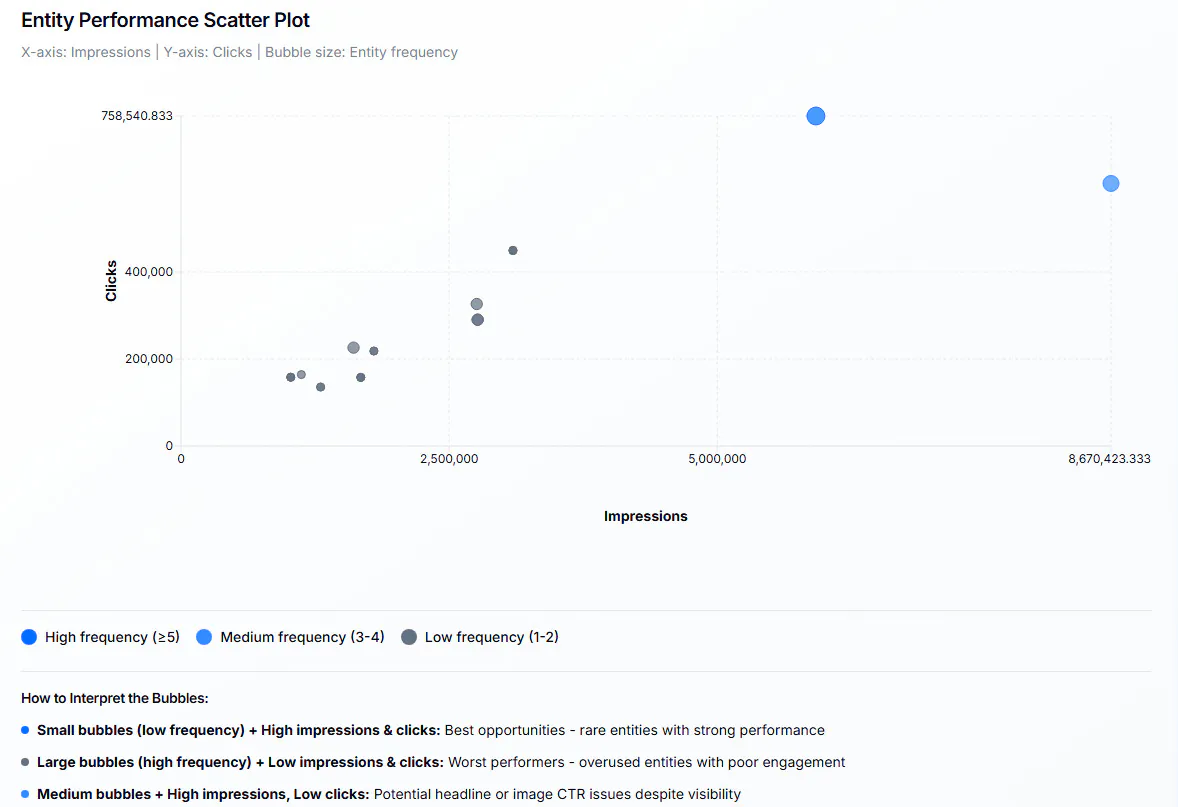
Sous‑dossiers et architecture
L’analyse par sous‑dossier est simple mais utile : elle indique quelles rubriques ou chemins d’URL génèrent le plus d’impressions et de clics sur Discover. Sur des sites volumineux, cette granularité devient stratégique.
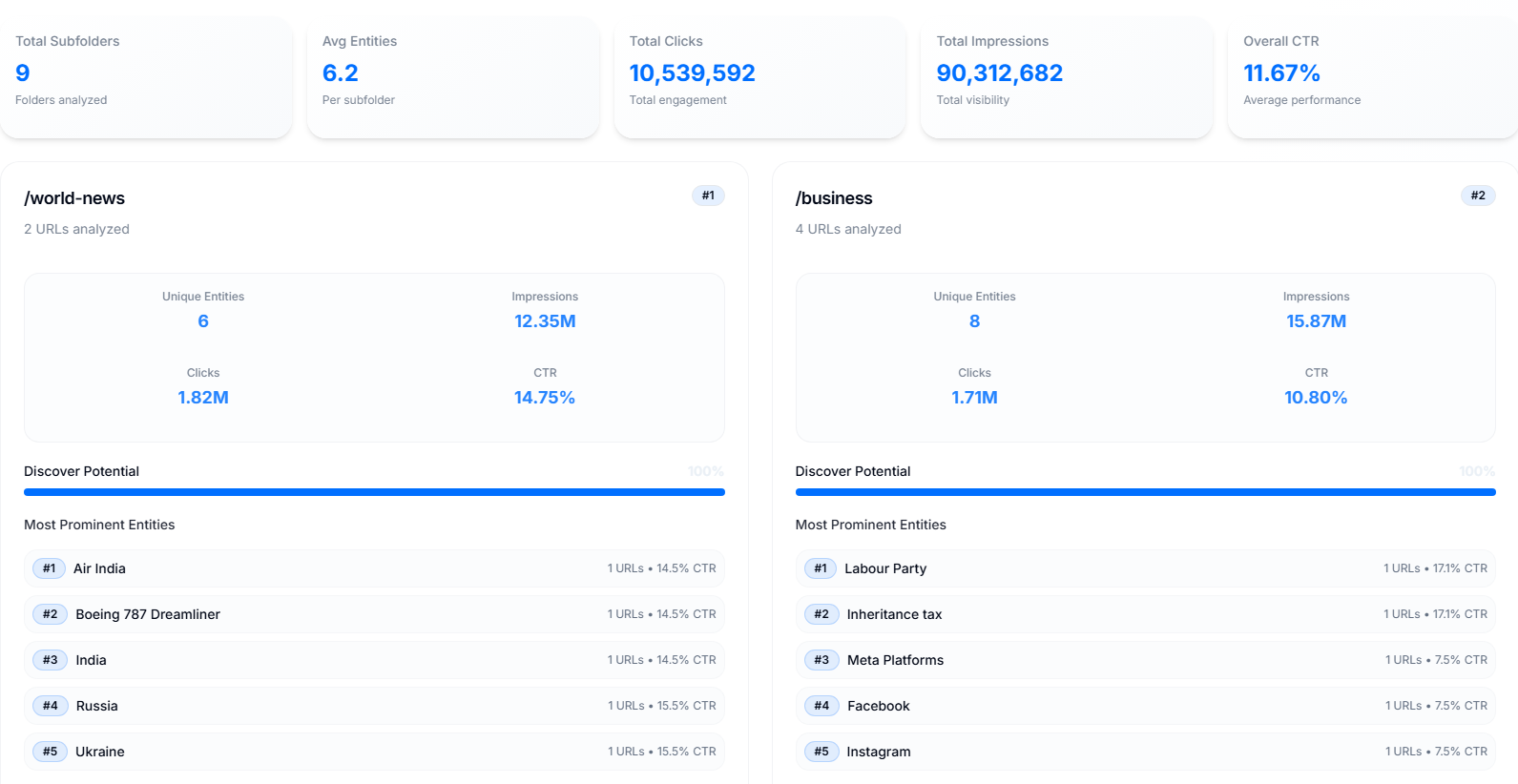
En croisant ces données avec les types de titres et les entités, on peut orienter les rédacteurs et les responsables de rubrique vers des formats plus propices à la réussite sur Discover.
Les sous‑dossiers performants donnent à chaque article une meilleure chance de visibilité initiale.
Un point de départ pratique : lister tous vos sous‑dossiers (ou vos thématiques si l’architecture est moins claire) et mesurer les clics, impressions et le CTR global puis moyen par article.
Auteur et signalement de la paternité
Google tient compte de l’auteur dans son écosystème de recherche. La personne qui signe un contenu a une influence sur les signaux de E‑E‑A‑T (Experience, Expertise, Authoritativeness, Trustworthiness).
La part exacte de l’auteur dans l’algorithme reste difficile à quantifier, mais les données et fuites montrent une attention notable portée à l’identification précise des auteurs.
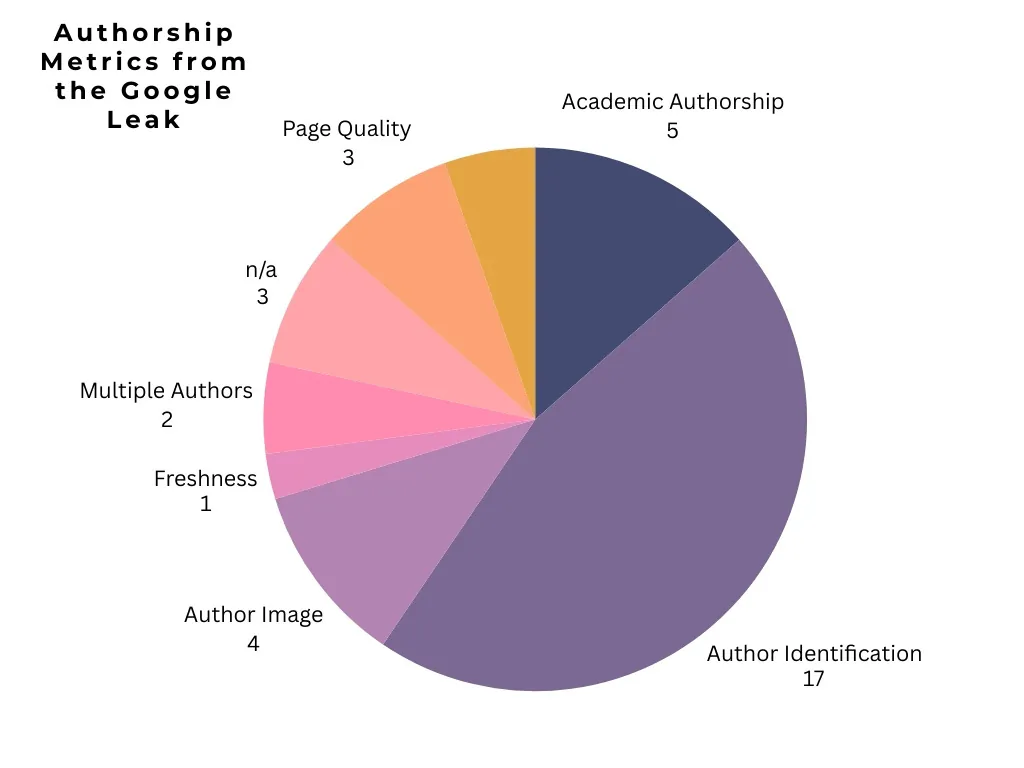
La désambiguïsation (disambiguation) est un concept central du SEO moderne : SEO sémantique, graphes de connaissances, données structurées, et principes de E‑E‑A‑T visent à limiter les faux contenus et la désinformation.
Pour Discover, il est utile d’évaluer les auteurs selon plusieurs critères :
- Combien d’articles de cet auteur apparaissent dans Discover et dans les résultats de recherche ?
- Quels sujets ou quelles entités lui réussissent le mieux ?
- Quelles catégories de titres produisent le meilleur CTR pour cet auteur ?
Types de titres et catégorisation
Analyser les formats de titres est une méthode efficace pour repérer ce qui fonctionne. Par exemple, les titres de type curiosity gap génèrent‑ils un CTR supérieur ? Les titres contenant des chiffres performent‑ils mieux ?
- Les célébrités dans les titres améliorent‑elles les performances ?
- Ces effets varient‑ils selon les sous‑dossiers ?
- Les titres à la première personne attirent‑ils davantage dans certaines rubriques ?
Ces questions doivent être transformées en hypothèses testables. Même si Discover n’est pas recelable via scraping direct, on peut estimer quel élément (H1, balise title, OG title) attire le plus de clics.
Commencez par définir vos catégories de titres : curiosity gap, localisé, listes numérotées, questions, tutoriels/« how‑to », accroches émotionnelles, première personne, etc., puis mesurez leur efficacité.
L’automatisation peut aider : utilisez un modèle de machine learning (par exemple via l’API ChatGPT) pour classer les titres et repérer les motifs (nombres, lieux, formulations interrogatives, première personne).
- Entraînez le modèle à détecter les noms de lieux, les chiffres, les questions et les tournures en première personne.
- Contrôlez la qualité de la catégorisation.
- Segmentez ensuite par sous‑dossier, auteur, entité, ou autres dimensions souhaitées.
Il est utile de garder à l’esprit que Google utilise plusieurs variantes de titres pour juger une page (H1, title, OG title). Discover semble privilégier l’OG title plus souvent que la recherche classique, ce qui laisse la possibilité d’un titre plus « clicky » au niveau OG sans impacter le H1.
Images : rôle et catégorisation
Les images jouent un rôle aussi important que les titres. On ne peut pas garantir quelle image sera systématiquement utilisée par Discover, mais si votre image mise en avant fait au moins 1200 px de largeur, il est probable qu’elle soit retenue (référence Google).
À court terme, le CTR semble être le levier principal pour la visibilité initiale ; à plus long terme, des signaux d’engagement sur la page (ce que certains appellent Navboost) prennent le relais.
Le CTR dans Discover dépend essentiellement de deux éléments sous votre contrôle :
- Le titre.
- L’image.
Dans la pratique éditoriale, certains schémas d’images tendent à mieux fonctionner selon les thématiques : en information générale, les visages exprimant la tristesse attirent ; dans les rubriques finance, les portraits directs et souriants inspirent plus de confiance.
Il est recommandé de constituer un jeu d’images annotées pour entraîner des modèles qui classent les photos selon des critères simples : présence humaine, direction du regard, expression faciale, composition, palette de couleurs, type de photo.
Catégorisez les images selon :
- Présence humaine et direction du regard.
- Expression faciale.
- Résonance émotionnelle.
- Composition et cadrage.
- Schémas de couleurs.
- Type de photo (portrait, scène, illustration, capture d’écran).
Puis utilisez l’apprentissage automatique pour regrouper les photos en « buckets » afin d’évaluer leur impact sur le CTR.
Performance de publication
Plus le volume éditorial est important, plus l’optimisation des horaires, des jours et de la fraîcheur devient pertinente. Les grandes rédactions analysent régulièrement ces paramètres à l’échelle des desks.
Si votre site place moins d’une cinquantaine d’articles par mois dans Discover, cette granularité peut sembler disproportionnée. En revanche, pour des centaines ou des milliers d’articles, ces informations sont précieuses pour les planneurs éditoriaux.
Les éléments à suivre sont notamment :
- Jours de publication.
- Heures de publication.
- Fraîcheur du contenu (actualisation vs article neuf).
- Ré‑publication (mise à jour) vs publication initiale.
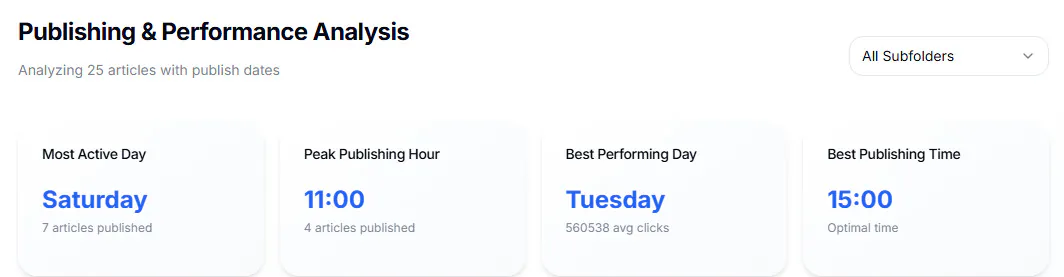
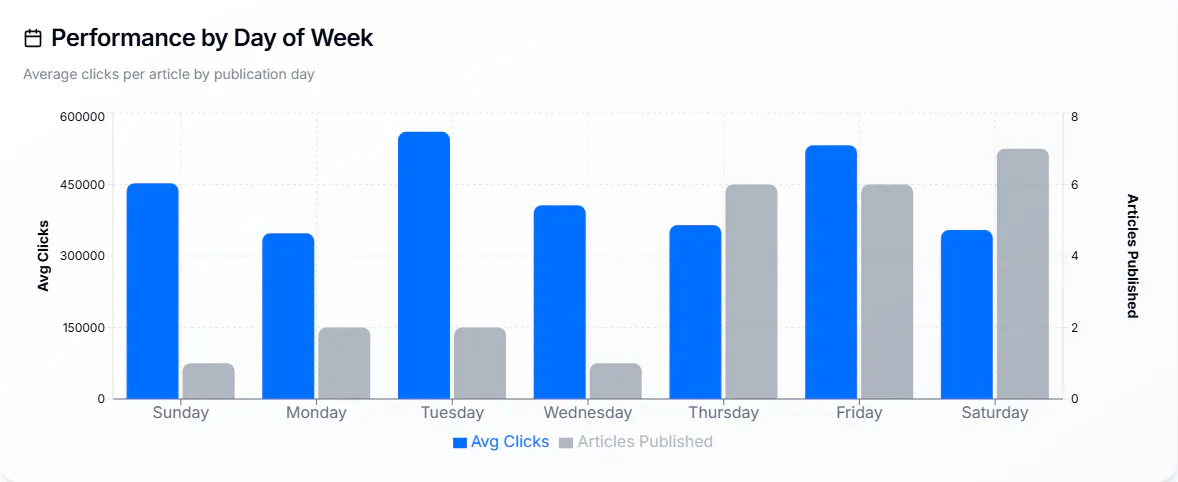
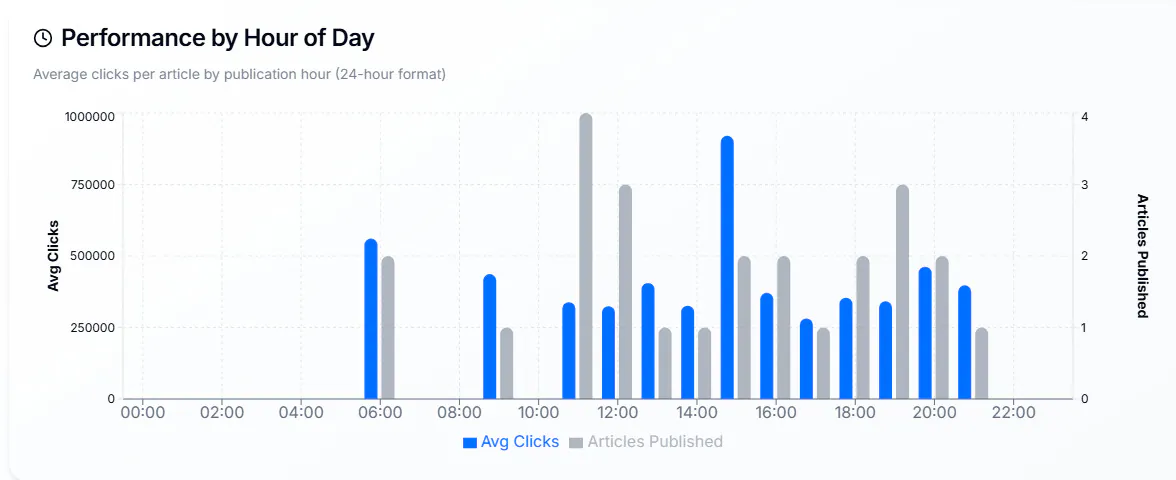
L’objectif de ces analyses est de fournir des recommandations opérationnelles aux desks et aux éditeurs : quels moments favorisent le pic de performance sur Discover ?
Il n’est pas recommandé de baser la stratégie éditoriale uniquement sur Discover. La plate‑forme est volatile et peut inciter à produire du contenu sensationnaliste qui n’apporte pas de valeur durable. Son impact direct sur les résultats business est souvent limité.
Comment articuler ces analyses en pratique ?
La première étape consiste à définir des objectifs clairs, mesurables et directement liés à la valeur générée par vos contenus sur Discover. Lors de la conception de vos analyses, concentrez‑vous sur les leviers sur lesquels vous pouvez agir.
Par exemple, peut‑être n’avez‑vous pas la main sur les sujets choisis par les rédacteurs, mais vous pouvez modifier les titres (H1, balise title, OG title) et les images avant publication.
- Formulez un objectif mesurable : trafic, conversions, ou visibilité accrue depuis Discover.
- Identifiez les paramètres sur lesquels vous avez une influence directe.
- Fournissez des recommandations au niveau desk ou sous‑dossier pour rendre ces actions pratiques et opérationnelles.
Il est utile de clarifier si votre rôle est plutôt stratégique ou tactique. Les profils stratégiques conseillent et orientent — ils proposent des lignes directrices sur le choix des entités ou des types de titres à éviter ou privilégier. Les rôles tactiques exécutent et ajustent : ils changent les titres, programment les heures de publication, optimisent les images, etc.
Ces principes sont simples, mais leur mise en œuvre systématique produit des gains mesurables lorsque l’analyse est correctement reliée à l’exécution éditoriale.
Ressources complémentaires :
Ce billet est une adaptation d’un article initialement publié sur Leadership in SEO.
Image à la Une : Master1305/Shutterstock


