Deux points de vue opposés sur les mêmes demandes
Une analyse réalisée par BrightEdge en juillet 2025 met en lumière des différences marquées entre les réponses proposées par ChatGPT …
Sommaire
- 1Deux approches distinctes des systèmes d’IA dans la réponse aux recherches
- 2Variations sectorielles : où la divergence est-elle la plus marquée ?
- 3Conséquences pratiques pour les éditeurs, les marques et la stratégie de contenu
- 4Mesures, limites et considérations réglementaires
- 5Perspectives et recommandations pour anticiper l’évolution des moteurs IA
- 6Articles connexes
Une analyse réalisée par BrightEdge en juillet 2025 met en lumière des différences marquées entre les réponses proposées par ChatGPT et celles fournies par le AI Mode de Google, dont le déploiement progressif en France interroge les pratiques de recherche. Selon l’étude, selon la nature de la requête, ces deux systèmes produisent des contenus qui s’orientent souvent vers des finalités distinctes.
Deux approches distinctes des systèmes d’IA dans la réponse aux recherches
L’enquête conduite par BrightEdge s’appuie sur l’analyse de plusieurs milliers de requêtes réparties dans quatre univers : la santé, la finance, l’éducation et la technologie B2B. Les auteurs ont comparé les sorties de ChatGPT (exploité avec le modèle GPT-4) et celles émises par le AI Mode de Google, en soumettant identiquement les mêmes formulations à chacune des deux plateformes via la plateforme d’analyse AI Catalyst.
Les résultats montrent une séparation nette selon le type d’intention exprimée par l’utilisateur. Pour des requêtes comparatives (par exemple « les meilleures cartes de crédit » ou « meilleures plateformes pour apprendre »), les deux intelligences artificielles tendent à produire des listes et des comparaisons assez proches. En revanche, quand la requête comporte une dimension pratique ou opérationnelle — c’est-à-dire une volonté explicite de passer à l’action — les réponses divergent sensiblement.
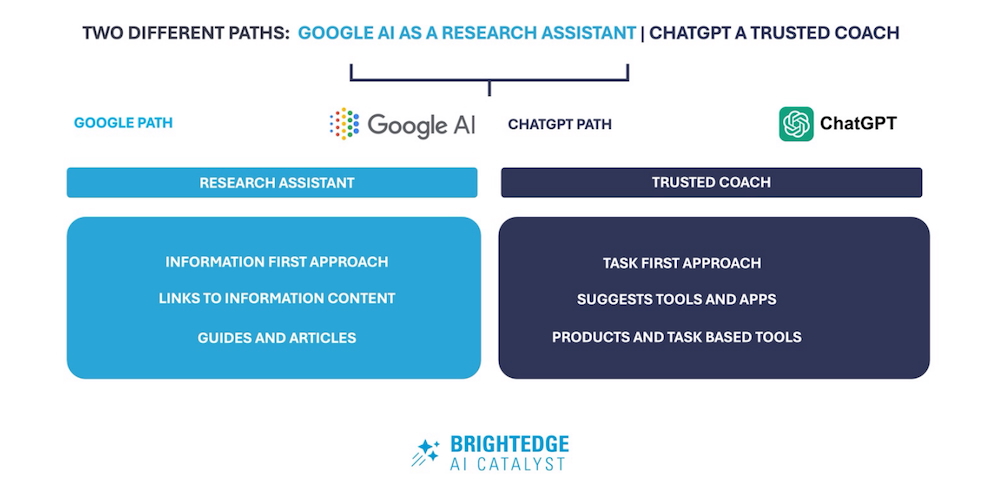
Nous sommes à une phase importante de transformation de la recherche en ligne : ChatGPT et le AI Mode de Google semblent suivre deux trajectoires distinctes dès que l’utilisateur demande des indications pour exécuter une tâche.
Concrètement, ChatGPT privilégie une orientation pragmatique. Il délivre fréquemment des recommandations d’outils, d’applications ou de services utilisables immédiatement, en citant des noms précis et en proposant parfois des étapes détaillées. À l’inverse, le AI Mode de Google renvoie plus souvent vers des pages explicatives : guides, articles institutionnels, notices officielles ou ressources de référence. Cette dichotomie renvoie à deux conceptions de la recherche : l’une orientée vers l’exécution et la conversion, l’autre davantage tournée vers l’information et la découverte.
Dans le langage du marketing et de l’analyse des parcours, BrightEdge qualifie les réponses de ChatGPT de « bottom of funnel » — c’est-à-dire davantage adaptées à une intention d’action ou d’achat — tandis que Google conserve une logique de navigation plus académique ou exploratoire. Cette distinction a des conséquences sur la manière dont le contenu doit être conçu et structuré pour être pertinent selon le canal d’accès.
Variations sectorielles : où la divergence est-elle la plus marquée ?
Le degré de divergence entre ChatGPT et le AI Mode dépend fortement du domaine étudié. L’analyse sectorielle menée par BrightEdge fait apparaître des écarts notables, tant dans la nature des sources citées que dans la granularité des conseils prodigués.
La santé est la catégorie où la différence est la plus prononcée : environ 62 % des réponses étudiées diffèrent entre les deux plateformes. Par exemple, à la requête « comment trouver un médecin », ChatGPT peut renvoyer un utilisateur vers des plateformes de prise de rendez-vous en ligne (il cite parfois des services comparables à Doctolib, comme Zocdoc aux États-Unis), tandis que le AI Mode privilégie généralement des annuaires hospitaliers, des pages d’institutions médicales ou des fiches d’établissements de référence telles que celles proposées par des organisations reconnues (ex. : Mayo Clinic). Ce contraste reflète à la fois des différences de priorisation des sources et des impératifs de fiabilité ou de responsabilité dans les réponses liées à la santé.
Dans le segment B2B tech, l’écart observé est de l’ordre de 47 %. À une requête pratique telle que « comment déployer une application », ChatGPT a tendance à orienter vers des outils et commandes techniques spécifiques — par exemple des solutions comme Kubernetes ou des interfaces en ligne de commande comme AWS CLI — et à proposer des étapes concrètes de mise en œuvre. Le AI Mode, quant à lui, privilégie des ressources documentaires : pages d’aide officielles, tutoriels de fournisseurs ou échanges techniques postés sur des forums de développeurs (par ex. Stack Overflow). Cette divergence révèle une différence de positionnement : assistant d’exécution versus portail documentaire.
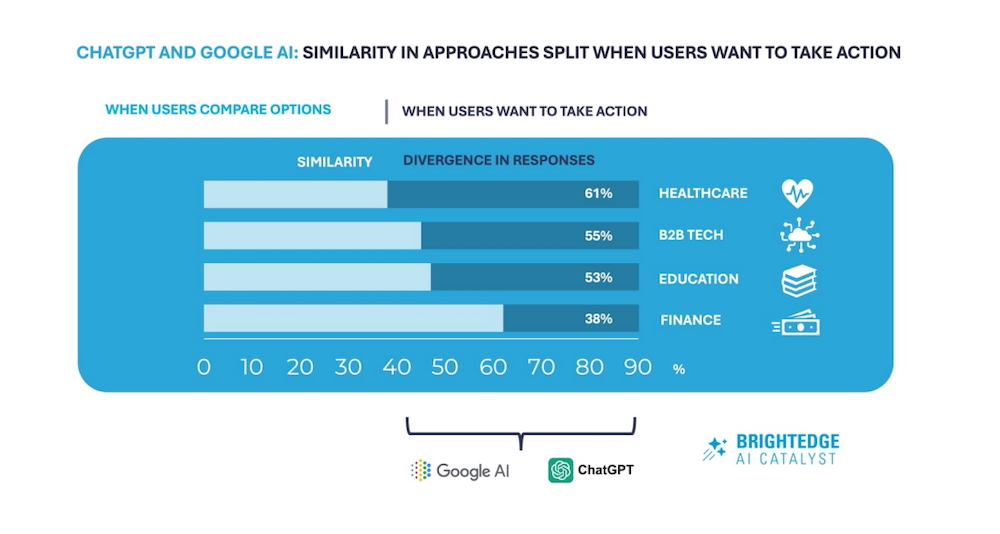
En éducation, la divergence moyenne est d’environ 45 %. Pour l’intention « comment apprendre Python », ChatGPT identifie fréquemment des plateformes commerciales proposant des cours structurés (citations d’acteurs comme Udemy) et recommande parfois des parcours pédagogiques progressifs. Le AI Mode renvoie davantage vers des contenus communautaires ou open source (ex. : dépôts GitHub, articles techniques sur Medium) et vers des ressources gratuites. Les deux systèmes reconnaissent cependant les grandes plateformes établies (par ex. Coursera, edX, LinkedIn Learning) lorsqu’il s’agit de comparaisons générales.
Le secteur de la finance présente le taux de divergence le plus faible parmi les quatre : autour de 39 %. Néanmoins l’écart demeure significatif. Pour une requête type « comment établir un budget », ChatGPT propose souvent des applications concrètes comme Mint ou YNAB (You Need A Budget), tandis que Google renvoie davantage vers des articles analytiques, des guides ou des comparateurs tels que NerdWallet. Cette différence tient en partie aux exigences réglementaires et à la nécessité d’afficher des sources vérifiables pour les contenus financiers, mais elle illustre aussi la tendance de ChatGPT à prioriser des solutions immédiatement exploitables.
Plusieurs facteurs expliquent ces écarts : les bases de données et les modalités d’entraînement des modèles, les critères de sélection des sources (fiabilité, autorité, fraîcheur), ainsi que l’objectif implicite assigné à chaque système (assistant conversationnel vs moteur de recherche enrichi). Pour les acteurs du contenu, ces différences impliquent des stratégies éditoriales distinctes selon le canal visé et la nature des requêtes que leurs audiences posent.
Conséquences pratiques pour les éditeurs, les marques et la stratégie de contenu
La montée en puissance des outils d’IA générative transforme des pans entiers de la recherche en ligne et pose de nouveaux défis aux détenteurs de contenu. Malgré la domination de Google (estimée à environ 90 % de parts de marché pour la recherche classique), des interfaces conversationnelles alimentées par des modèles comme ChatGPT occupent désormais une place grandissante dans les parcours utilisateurs, en particulier pour les requêtes à vocation opérationnelle.
Selon BrightEdge, sur l’échantillon analysé, ChatGPT fait apparaître des marques, des produits ou des services spécifiques environ deux fois plus fréquemment que Google, surtout lorsque l’utilisateur formule une intention claire de type « comment faire » ou « quel outil utiliser ». Cette évolution change le mode d’apparition des acteurs dans les réponses automatisées : il ne suffit plus d’être bien positionné sur les pages de résultats traditionnelles — il faut aussi être « actionnable » ou identifiable par les modèles conversationnels.
Pour les requêtes orientées vers l’action, ChatGPT propose massivement des outils et applications de façon directe, alors que Google demeure plus enclin à pointer vers du contenu explicatif.
Les implications principales se déclinent ainsi :
- Rôle du référencement : le SEO classique conserve son importance, mais son périmètre s’élargit. Au-delà du positionnement traditionnel (mots-clés, backlinks, autorité), il devient stratégique d’optimiser la structure du contenu pour qu’il soit facilement assimilable par des modèles d’IA : usages d’énumérations claires, étapes numérotées, extraits concis, balisage sémantique (schema.org, JSON‑LD pour FAQ, HowTo, Product, Organization).
- Format du contenu : produire à la fois des contenus « explicatifs » (articles, revues, études) susceptibles d’être cités par Google et des contenus « actionnables » (guides pratiques, listes d’outils, tutoriels pas-à-pas) susceptibles d’être repris par des assistants comme ChatGPT. Les différences observées incitent donc à une diversification des formats.
- Visibilité des marques : être explicitement nommé dans le texte (nom de produit, nom d’entreprise) semble augmenter les chances d’être cité par certains modèles. Cependant, il faut veiller aux exigences de neutralité et de transparence : la mention de marques doit s’appuyer sur des éléments factuels et vérifiables.
- Autorité et fiabilité : Google continue de valoriser les signaux d’autorité (références, citations institutionnelles, E‑E‑A‑T — expérience, expertise, autorité, fiabilité). Pour les contenus sensibles (santé, finance), le poids des sources reconnues demeure crucial pour apparaître dans les résultats du AI Mode.
- Suivi et attribution : la traçabilité des visites issues d’interactions avec des IA conversationnelles est plus complexe que pour une navigation web classique. Les éditeurs devront adapter leurs outils d’analyse pour mesurer l’impact réel de ces nouveaux points de contact sur l’engagement, la conversion et la notoriété.
Pour répondre à ces enjeux, voici des principes d’adaptation, sans constituer des prescriptions commerciales mais plutôt des pistes d’optimisation :
- Documenter de façon structurée : intégrer des sections « étapes à suivre », « outils recommandés », « liens officiels » au sein des contenus pour faciliter l’extraction d’information par les modèles d’IA.
- Standardiser le balisage : utiliser des schémas HowTo, FAQ et Product pour signaler explicitement la nature des éléments susceptibles d’être repris par des assistants.
- Maintenir la rigueur factuelle : pour les thèmes sensibles (santé, finance), afficher des références, des dates de mise à jour et des profils d’auteurs qualifiés afin de renforcer la confiance des algorithmes et des lecteurs.
- Penser en multi-format : produire des versions courtes (résumés, bullets), des versions techniques (tutoriels, commandes) et des versions contextuelles (analyses, études) pour couvrir l’ensemble des intentions de recherche.
- Surveiller les citations de marque : analyser la fréquence et le contexte des mentions de produits/entreprises dans les réponses générées par ChatGPT et autres IA afin d’évaluer les opportunités et les risques de réputation.
Techniquement, certaines pratiques peuvent aider à être détectable par les modèles : structurer logiquement les pages, publier des données ouvertes et vérifiables, fournir des extraits concis répondant à des questions spécifiques, et s’assurer que les ressources officielles sont clairement identifiables (pages « À propos », contacts institutionnels, politiques éditoriales). Toutefois, ces recommandations ne garantissent pas une citation automatique par un modèle d’IA, qui reste dépendante de sa base d’entraînement, de ses filtres et de ses règles internes.
Du point de vue économique, la capacité d’un modèle à recommander des produits ou des services représente une opportunité potentielle pour certains modèles d’affaires (affiliation, intégration de services), mais soulève également des questions éthiques et réglementaires, notamment sur la transparence des critères de sélection et le traitement des conflits d’intérêts.
Mesures, limites et considérations réglementaires
L’étude de BrightEdge éclaire des tendances, mais elle comporte aussi des limites inhérentes à ce type d’analyse comparative. Les modèles évoluent rapidement : mises à jour de GPT-4, adaptations du AI Mode, variations régionales des bases de données et réglages des systèmes peuvent modifier les résultats en peu de temps. De plus, l’apparition d’une réponse par l’un ou l’autre système dépend souvent de paramètres non visibles pour l’utilisateur (filtres de confiance, pondération des sources, données propriétaires).
Sur le plan réglementaire, plusieurs questions méritent attention :
- Responsabilité : qui est responsable en cas d’erreur dans une réponse actionable fournie par une IA ? Les réponses techniques ou médicales qui orientent vers une action peuvent avoir des conséquences réelles, d’où la nécessité de préciser les limites de compétence des assistants.
- Transparence : savoir si et comment une IA recommande un produit en raison d’un partenariat commercial ou d’un biais de formation est un enjeu important pour la confiance des utilisateurs.
- Protection des données : l’interaction avec des assistants peut impliquer des informations personnelles ; il convient de clarifier les pratiques de collecte et de réutilisation des données.
- Conformité sectorielle : notamment pour la santé et la finance, les réponses doivent respecter des cadres réglementaires spécifiques afin d’éviter la diffusion de conseils non conformes.
Enfin, la dimension internationale est à considérer : les outils et les sources privilégiés varient selon les marchés (ex. : Doctolib en France, Zocdoc aux États-Unis). Les éditeurs internationaux doivent donc adapter leurs contenus en tenant compte des spécificités locales si l’objectif est d’être pertinent pour des assistants entraînés sur des jeux de données multilingues et multirégionaux.
Perspectives et recommandations pour anticiper l’évolution des moteurs IA
À l’horizon, plusieurs scénarios sont plausibles. On peut s’attendre soit à une convergence progressive des approches — les systèmes alignant leurs priorités entre information et action — soit à une spécialisation durable, où certains assistants se positionneront comme des prescripteurs opérationnels et d’autres comme des indexeurs de référence. Dans tous les cas, les organisations productrices de contenu disposent de marges de manœuvre pour rester visibles et utiles :
- Produire des contenus clairs et modulaires : sections « ce qu’il faut faire », « outils recommandés », « ressources officielles » qui facilitent l’extraction d’informations.
- Soigner la qualification des auteurs et la transparence éditoriale pour renforcer l’autorité perçue par des systèmes valorisant la fiabilité.
- Mettre en place des formats structurés (FAQ, HowTo, Product) et des métadonnées explicites pour faciliter l’intégration automatisée.
- Surveiller activement les mentions et les patterns de citation : analyses régulières des réponses émises par différents assistants pour détecter les opportunités et les risques.
- Développer des synergies entre équipes techniques et éditoriales : le SEO, la data et la rédaction doivent converger pour anticiper les évolutions des usages de recherche.
Ces orientations ne prétendent pas à l’exhaustivité, mais elles constituent un cadre de travail pour comprendre et s’adapter à la complexité croissante des interactions entre utilisateurs, contenus et intelligences artificielles.
En conclusion, l’étude de BrightEdge met en exergue une tension fondamentale : la coexistence d’un modèle conversationnel orienté vers l’action (ChatGPT) et d’un modèle conservant l’approche documentaire et référentielle (AI Mode de Google). Pour les éditeurs, les marques et les acteurs du SEO, cette réalité impose de repenser la production de contenu en vue de couvrir des intentions multiples — de la découverte à l’exécution — et d’adopter des formats et des pratiques susceptibles d’être exploités par des systèmes d’IA aux logiques différentes.
La transformation est en cours : mesurer, expérimenter et documenter restent des leviers essentiels pour naviguer dans cet environnement en mutation.
Articles similaires
 seo
seoMise à jour des liens du mode IA de Google, données sur la part de clics et propagation de ChatGPT — actualité SEO
 seo
seoJouez pour gagner un exemplaire de « SEO sans migraine », premier ouvrage d’Amandine Bart
 seo
seo