Google minimise le rôle du GEO — parlons des résultats d’IA de mauvaise qualité
Lors d’un épisode du podcast Search Off The Record, Danny Sullivan et John Mueller de Google ont répondu à des …
Sommaire
- 1Le paysage du SEO face à la nouvelle génération de recherche
- 2Rédiger pour des réponses longues : principes et conséquences
- 3, etc.), les listes, et les paragraphes donnent au contenu une architecture exploitable par les systèmes automatiques tout en restant lisible pour les visiteurs. Transformer toutes les pages en mosaïques de micro-blocs rédigés en permanence pour l’algorithme risque d’appauvrir l’expérience utilisateur sans garantir de gains pérennes en visibilité. Face à ces recommandations, Danny Sullivan s’est montré explicite : ne pas systématiquement morceler les textes en petits segments destinés aux LLM. Il a partagé son point de vue après échange avec des ingénieurs, insistant sur le fait que les pages doivent être préparées pour des lecteurs humains en premier lieu, et non pour satisfaire des heuristiques provisoires. Dans ses propos, il a insisté sur l’idée que l’on ne devrait pas créer deux versions d’un même contenu — l’une optimisée pour les modèles, l’autre pour la navigation classique — et que la pratique de fractionner à outrance était déconseillée. L’objectif doit rester la lisibilité et la valeur pour l’être humain, car c’est ce que les systèmes cherchent, à terme, à récompenser. Le débat qu’il fallait plutôt aborder : le query fan-out et la baisse des référents
- 4Penser sur le long terme : se concentrer sur les fondamentaux
- 5Les résultats « brouillons » générés par l’IA : une préoccupation réelle
- aL’absence croissante d’expertise spécialisée
- 6Le mode IA de Google valorise parfois des pages sans expertise
- aLes contenus de haute qualité sont parfois relégués dans « Plus » > « Actualités »
- bCapture d’écran des résultats expert cachés
- 7GEO, AEO, SEO : les labels importent moins que la réalité
- 8Perspectives et recommandations pour les éditeurs
- 9Conclusion — Ce que change vraiment l’ère des LLM
- aArticles connexes
Lors d’un épisode du podcast Search Off The Record, Danny Sullivan et John Mueller de Google ont répondu à des questions d’éditeurs et de spécialistes du SEO concernant le classement dans les environnements de recherche basés sur les LLM et les interfaces de type chat. Ils ont notamment récusé la recommandation répandue consistant à « découper » systématiquement le contenu en petites unités — le fameux conseil de chunking. Toutefois, au-delà de ce point précis, la discussion aurait pu aborder des enjeux plus urgents liés à l’évolution de la recherche et à l’impact sur le trafic des sites experts.
Le paysage du SEO face à la nouvelle génération de recherche
Historiquement, Google s’appuyait largement sur le rapprochement de chaînes de caractères : le matching de mots-clés, soutenu par le système de PageRank et par l’analyse des anchor text des liens. L’arrivée du Knowledge Graph en 2012 a amorcé une réflexion différente : classer des réponses en se basant sur des entités réelles, c’est-à-dire passer des « chaînes » aux « choses ». Ce glissement a préparé le terrain à des approches de recherche qui raisonnent davantage en termes de concepts qu’en simples mots clés.
Aujourd’hui, ce que Google décrivait comme « la prochaine génération de la recherche » se traduit par des systèmes capables d’extraire et de synthétiser l’intelligence collective du web pour fournir des réponses plus structurées et contextuelles, parfois rédigées sous forme d’articles de longueur moyenne ou longue.
Dire que « rien n’a changé » pour le SEO est partiellement vrai : le moteur reste la même plateforme technique. Mais ce qui évolue, c’est la forme des réponses : elles sont de plus en plus longues, multi-paragraphes, et visent à couvrir plusieurs angles d’un sujet en répondant à d’autres requêtes dérivées de la question initiale. En conséquence, le paradigme d’optimiser une page pour un seul mot-clé et un seul résultat est profondément remis en cause par le phénomène de query fan-out.
C’est dans ce contexte que Danny Sullivan et John Mueller ont essayé d’orienter les pratiques des professionnels du SEO et des éditeurs. Leurs recommandations méritent d’être examinées, mais elles ne traitent pas tous les sujets prioritaires pour les créateurs de contenu.
Rédiger pour des réponses longues : principes et conséquences
Avec la montée des réponses multi-paragraphes, la question revient souvent : faut-il maintenant structurer chaque page en petites briques indépendantes pour que les modèles de LLM « ingèrent » mieux le contenu ? Cette idée de partir de courts « blocs » repose souvent sur l’intuition que les modèles préfèrent des unités atomiques. Pourtant, cette approche ignore que le balisage HTML standard (titres, listes ordonnées ou non, paragraphes balisés) offre déjà une logique de découpage compréhensible pour les machines et les lecteurs humains.
Un document correctement structuré en HTML est, par définition, fragmenté en sections logiques. Les en-têtes (
,
, etc.), les listes, et les paragraphes donnent au contenu une architecture exploitable par les systèmes automatiques tout en restant lisible pour les visiteurs. Transformer toutes les pages en mosaïques de micro-blocs rédigés en permanence pour l’algorithme risque d’appauvrir l’expérience utilisateur sans garantir de gains pérennes en visibilité.
Face à ces recommandations, Danny Sullivan s’est montré explicite : ne pas systématiquement morceler les textes en petits segments destinés aux LLM. Il a partagé son point de vue après échange avec des ingénieurs, insistant sur le fait que les pages doivent être préparées pour des lecteurs humains en premier lieu, et non pour satisfaire des heuristiques provisoires.
Dans ses propos, il a insisté sur l’idée que l’on ne devrait pas créer deux versions d’un même contenu — l’une optimisée pour les modèles, l’autre pour la navigation classique — et que la pratique de fractionner à outrance était déconseillée. L’objectif doit rester la lisibilité et la valeur pour l’être humain, car c’est ce que les systèmes cherchent, à terme, à récompenser.
Le débat qu’il fallait plutôt aborder : le query fan-out et la baisse des référents
Plus déterminant à mes yeux que le débat sur le chunking est l’impact du phénomène de query fan-out sur les référents (les visites transmises par le moteur). Le concept est simple : pour chaque requête utilisateur, le moteur va produire un ensemble de réponses longues couvrant de multiples sous-questions. Autrement dit, une seule requête peut générer une myriade de chemins de reformulation, et ce sont souvent des pages différentes qui sont valorisées pour ces variantes.
Le résultat ? Le trafic fourni à chaque page peut se diluer, et les sites qui ont historiquement bénéficié d’un fort volume de visites organiques constatent une érosion du nombre d’impressions et de clics. Ce phénomène est aggravé lorsque les pages mises en avant par le moteur ne proviennent pas toujours des meilleures sources en termes d’expertise ou d’autorité.
Penser sur le long terme : se concentrer sur les fondamentaux
Danny Sullivan a également rappelé un principe important pour les responsables de contenu : toute tactique spécifiquement conçue pour séduire un système technique a un risque d’obsolescence. Les algorithmes évoluent, et les optimisations étroites, visant uniquement à tirer parti d’un état temporaire d’un modèle, peuvent ne pas survivre aux mises à jour.
En substance, il a conseillé de privilégier des objectifs pérennes : produire du contenu clair, utile et ciblé pour des personnes réelles. Ce sont ces fondations — qualité, pertinence, clarté — qui tendent à offrir une résilience face aux évolutions des systèmes d’indexation et de synthèse.
Autrement dit, au-delà des astuces tactiques, les pratiques éprouvées de journalisme et d’édition numérique restent des valeurs sûres : travail sur l’angle, vérification des sources, structuration logique et traitement exhaustif des sujets.
Les résultats « brouillons » générés par l’IA : une préoccupation réelle
Il est utile de rappeler que l’intention affichée de nombreux porte-parole de Google est d’aider les éditeurs. Néanmoins, une préoccupation majeure demeure : la baisse des opportunités de trafic pour les sites experts et la multiplication de réponses de faible qualité — que l’on pourrait qualifier de « garbage » — dans les interfaces d’IA et les modes de recherche assistée.
L’absence croissante d’expertise spécialisée
Un phénomène observé ces derniers temps est la relégation visible des sites d’experts. Dans certains résultats, il faut désormais cliquer sur l’onglet « Plus » puis sur « Actualités » pour voir des articles issus de publications reconnues et spécialisées. Cette distance crée une barrière supplémentaire entre l’utilisateur et les sources de haute qualité, au profit de pages plus génériques ou moins fiables.
Comment Google dissimule parfois les pages d’experts
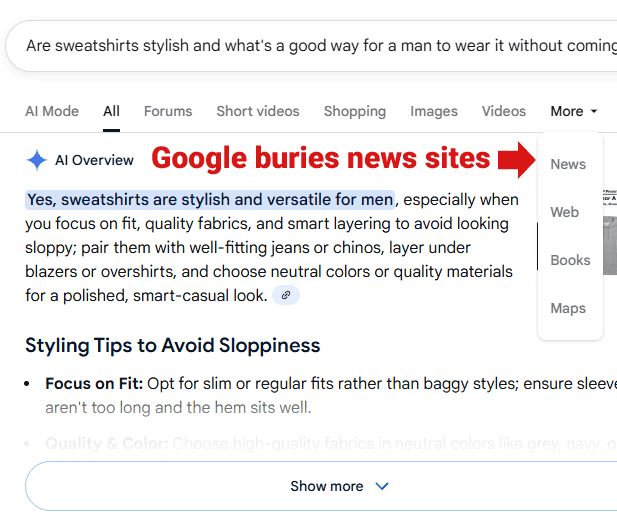
La capture ci‑dessus illustre visuellement comment des ressources de qualité peuvent se retrouver moins visibles, masquées derrière des options secondaires d’interface. Pour un utilisateur pressé, ce déplacement de la visibilité change radicalement l’accès au contenu expert.
Le mode IA de Google valorise parfois des pages sans expertise
Pour mesurer l’ampleur du problème, il suffit d’un exemple concret. Sur une requête banale portant sur le stylisme d’un sweatshirt, le mode IA du moteur a cité des pages peu pertinentes ou visiblement non spécialisées :
Exemples de pages citées par le mode IA :
1. Un billet Medium abandonné datant de 2018, dont le blog ne compte que deux publications et affiche des images cassées — peu d’indices d’autorité.
2. Un article publié sur LinkedIn, une plateforme professionnelle plutôt qu’un média d’expertise mode — pas l’endroit naturel pour des conseils stylistiques approfondis.
3. Un texte sur le site d’un revendeur de sneakers, qui n’est pas reconnu comme source autoritaire en matière de style vestimentaire.
Ces résultats ne semblent pas être des cas isolés ou des sélections injustifiées : ils traduisent une tendance observée sur plusieurs requêtes où des pages de faible valeur sont mises en avant par la synthèse automatique.
Capture d’écran des résultats de recherche peu convaincants
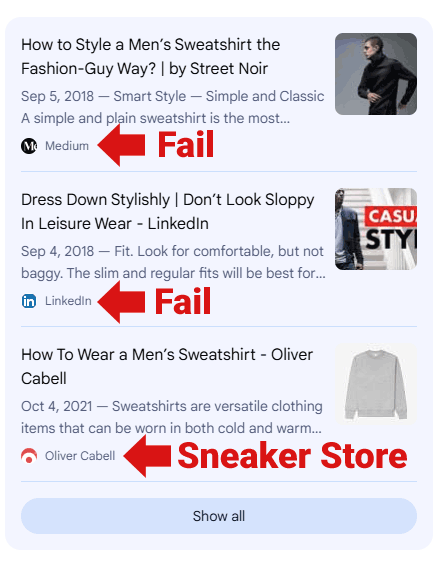
La capture précédente montre bien l’écart entre une requête légitime et les pages effectivement proposées par le générateur de réponses. Cette situation pose des questions sur les critères de sélection et sur la manière dont la qualité est évaluée par les systèmes d’agrégation.
Les contenus de haute qualité sont parfois relégués dans « Plus » > « Actualités »
Si l’on cherche des articles de fond produits par des titres reconnus — par exemple GQ ou le New York Times pour une question de mode — ils peuvent exister mais ne sont pas toujours mis en avant par défaut. L’interface pousse parfois l’utilisateur à explorer un onglet secondaire pour atteindre ces sources, au lieu de les présenter directement parmi les premières références.
Capture d’écran des résultats expert cachés
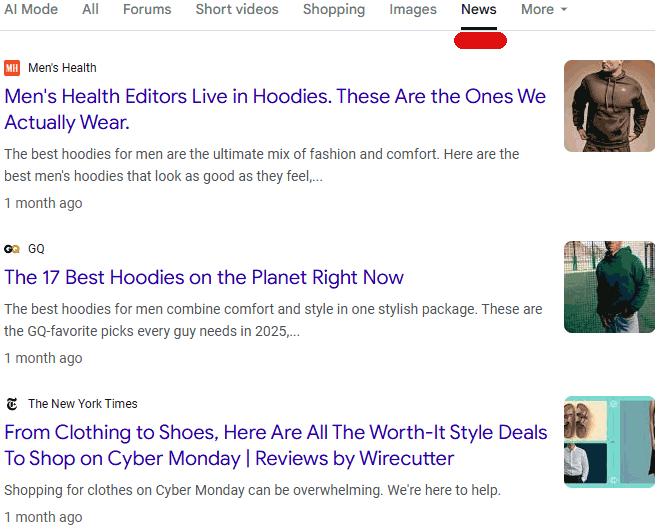
Cette seconde capture illustre les contenus de meilleure qualité qui existent pour la requête mais qui sont moins visibles par défaut. Pour les éditeurs professionnels, cette disparition relative de la visibilité entraîne une érosion du trafic et des opportunités de monétisation.
GEO, AEO, SEO : les labels importent moins que la réalité
Le débat sémantique autour de termes comme GEO (Generative Experience Optimization) ou AEO (Answer Engine Optimization) versus SEO est souvent animé et passionné. Mais au quotidien, ces catégories ne changent pas la problématique essentielle : des pages de qualité décroissent en visibilité et en trafic pendant que des contenus de moindre valeur occupent l’espace visible.
Ce glissement a des conséquences concrètes : moins de découvertes fortuites de sites intéressants, une expérience utilisateur plus plate, et une frustration croissante parmi les producteurs de contenu qui voient leurs efforts récompensés de moins en moins.
On assiste à une accumulation de résultats décevants — et ce constat n’est pas un simple caprice d’éditeur : il s’agit d’un signal que l’équilibre entre synthèse automatisée et mise en valeur des sources fiables mérite une révision.
Perspectives et recommandations pour les éditeurs
Que peuvent retenir les responsables de sites et les spécialistes du SEO de ces observations et des échanges publics de représentants de Google ? Voici quelques pistes de réflexion, formulées de manière neutre et pragmatique :
- Prioriser la valeur pour l’humain : continuer à produire des contenus approfondis, exacts et bien structurés, optimisés pour la compréhension humaine plutôt que pour des signaux ponctuels.
- Renforcer l’expertise et la crédibilité : mettre en avant les qualifications, les sources et les références pour aider les lecteurs et les systèmes à reconnaître l’autorité d’un site.
- Soigner le balisage : utiliser correctement les en-têtes, les listes, les données structurées (schema.org) et les méta-données pour faciliter l’analyse par les moteurs et par les assistants.
- Surveiller les métriques de trafic dans la durée : prêter attention aux changements d’impressions, aux clics, et aux tendances de positionnement liés au phénomène de query fan-out.
- Explorer la diversification d’audience : ne pas dépendre d’une seule source de trafic ; développer des canaux alternatifs (newsletters, réseaux sociaux, partenariats) pour compenser les variations algorithmiques.
Ces recommandations ne sont pas des formules miracles, mais elles alignent la stratégie éditoriale sur des critères qui restent robustes face aux évolutions techniques.
Conclusion — Ce que change vraiment l’ère des LLM
La transition vers des interfaces et des réponses alimentées par des LLM modifie sensiblement la manière dont les utilisateurs reçoivent l’information. Les effets les plus profonds ne sont pas uniquement techniques : ils sont économiques et éditoriaux. Le query fan-out dilue les opportunités de référencement, et la mise en valeur de pages de moindre qualité réduit la visibilité des sites experts.
Les propos de Danny Sullivan et John Mueller rappellent l’importance de concevoir du contenu pour des lecteurs humains et d’éviter des micro-optimisations temporaires. Cela dit, il serait utile que les discussions publiques traitent davantage des impacts sur la distribution du trafic et sur la capacité des sources spécialisées à rester visibles.
Pour les éditeurs, la feuille de route reste centrée sur la qualité, l’expertise et la clarté : ce sont ces éléments qui offrent la meilleure chance de résilience face aux mutations rapides des systèmes de recherche et de synthèse.
Image principale : Shutterstock/Kues


