Les 8 nouveautés SEO à ne pas rater cet été
À nouveau, Google a concentré l’attention des professionnels du référencement cet été, en déployant une seconde mise à jour majeure …
Sommaire
- 1Lancement de la June 2025 Core Update : ce qu’il faut retenir
- 2Déploiement de l’August 2025 Spam Update : renforcement des défenses anti-spam
- 3MUVERA et GFM : deux pierres angulaires du « nouveau » référencement
- 4Web Guide : une nouvelle forme d’organisation des pages de résultats
- 5L’impact de l’**IA** sur les parcours de recherche : enseignements d’études récentes
- 6Comment Perplexity choisit ses sources : résultats d’une analyse technique
- 7Des résumés automatisés dans Discover et une API pour Google Trends
- 8Correspondance limitée entre sources citées par les IA et les pages du top 10
- aArticles connexes
À nouveau, Google a concentré l’attention des professionnels du référencement cet été, en déployant une seconde mise à jour majeure de ses algorithmes fin juin, en lançant sa première mise à jour antispam de l’année à la fin août, et en présentant plusieurs innovations qui redessinent progressivement les pratiques du SEO. Parallèlement, des études indépendantes ont apporté des éclairages sur le classement opéré par Perplexity ou sur le faible recoupement entre les sources citées par les systèmes d’IA et les pages visibles dans les SERP. Ci-dessous, nous décryptons ces évolutions et leurs implications pour les sites web.
Lancement de la June 2025 Core Update : ce qu’il faut retenir
Le 30 juin, Google a annoncé via son compte officiel sur X le déploiement de la June 2025 Core Update, sa deuxième mise à jour algorithmique majeure de l’année après celle de mars. Fidèle à son rythme habituel, la société effectue en général ce type d’évolution technique tous les trois mois environ. Ces « core updates » ont pour objectif d’ajuster globalement le classement des pages en affinant la manière dont le moteur évalue la pertinence et la qualité des contenus.
Concrètement, une telle mise à jour peut provoquer des variations significatives de trafic pour certains sites : des gains notables peuvent côtoyer des pertes de position pour d’autres. Pour les professionnels du référencement, la période suivant un core update est donc propice à l’analyse des principaux indicateurs — positions, clics, taux de rebond, conversions — via les outils spécialisés et les consoles de suivi. Il est également conseillé de se référer aux recommandations officielles publiées par Google, qui rappellent les fondamentaux permettant de limiter le risque d’impact négatif : contenu utile et original, structure claire, expérience utilisateur de qualité, et signaux de confiance.
Au-delà des réactions immédiates aux fluctuations, la June 2025 Core Update illustre deux tendances durables : l’importance croissante de la compréhension sémantique des pages et la prise en compte accrue des signaux relatifs à la crédibilité et à l’autorité d’un site. Les algorithmes intègrent désormais des couches d’analyse plus fines, favorisant les ressources qui apportent une valeur ajoutée réelle à l’utilisateur plutôt que des pages construites uniquement pour capter du trafic.

Dans ce contexte, il devient essentiel pour les acteurs du SEO d’adopter une stratégie multi-dimensionnelle : audits techniques réguliers, production de contenus documentés et vérifiables, optimisation UX, et surveillance des signaux de réputation en ligne. Ces axes constituent des défenses contra-cycliques face aux ajustements systémiques opérés par des mises à jour comme la June 2025 Core Update.
Déploiement de l’August 2025 Spam Update : renforcement des défenses anti-spam
Fin août, Google a mis en place l’August 2025 Spam Update, la première intervention antispam majeure de l’année, annoncée le mardi 26 août. Cette mise à jour vise à améliorer les capacités de détection des pratiques frauduleuses ou manipulatrices qui altèrent la qualité des résultats de recherche. Les systèmes antispam évoluent régulièrement pour contrer des tactiques de plus en plus sophistiquées, qu’il s’agisse de réseaux de sites automatisés, de pages sur-optimisées ou d’assemblages de contenus générés massivement sans valeur ajoutée.
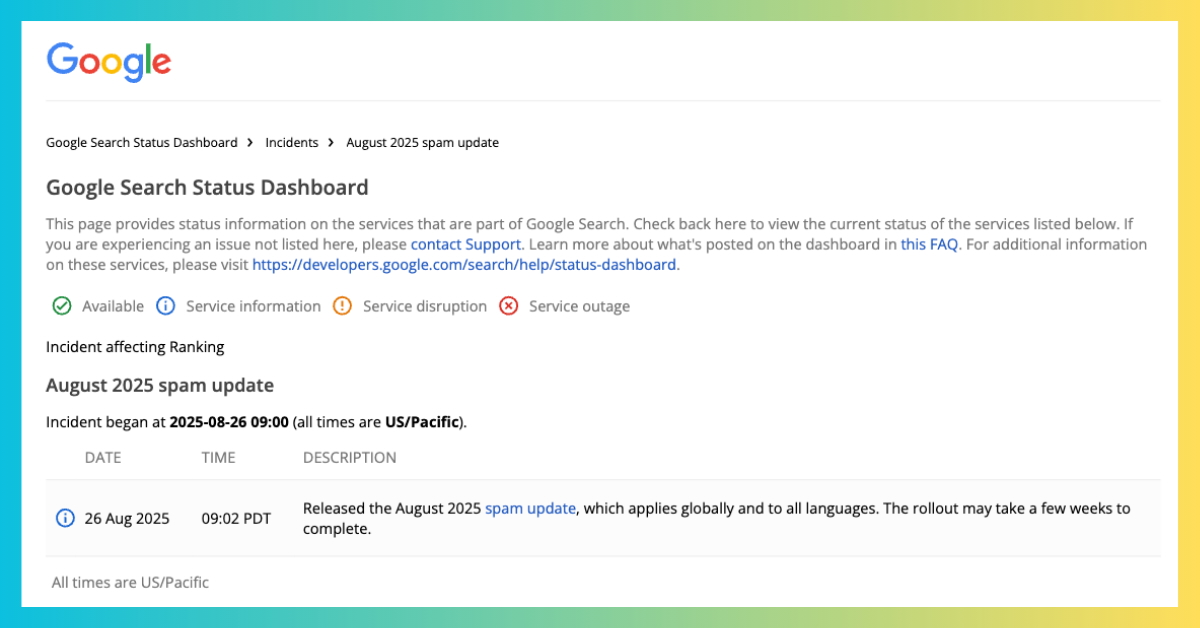
Ce type de mise à jour se déroule généralement en plusieurs phases, étalées sur plusieurs semaines, afin d’affiner les règles et d’éviter des effets collatéraux sur des sites légitimes. Les propriétaires de sites doivent rester vigilants aux signaux suivants, souvent ciblés par les filtres antispam : liens non naturels ou massifs, contenus dupliqués ou peu informatifs, pages créées uniquement pour capter des clics, et manipulations de balises structurées. Pour limiter le risque d’être pénalisé, la priorité est donnée à la transparence éditoriale, à la vérifiabilité des informations et à une gestion rigoureuse des liens entrants.
Pour les équipes techniques, l’arrivée d’un spam update implique de surveiller attentivement les notifications dans les consoles dédiées, d’examiner les variations de positionnement et de réaliser des audits de liens et de contenu. Corriger rapidement les pratiques identifiées comme potentiellement problématiques réduit la durée des impacts négatifs et facilite la récupération.
MUVERA et GFM : deux pierres angulaires du « nouveau » référencement
Au-delà des classiques ajustements, Google a présenté des avancées conceptuelles majeures qui modifient la manière dont le moteur appréhende l’information. Deux technologies méritent une attention particulière :
- MUVERA (pour Multi-Vector Retrieval via Fixed Dimensional Encodings) : ce mécanisme de récupération multi-vecteurs vise à accélérer et à fiabiliser l’identification de documents pertinents en combinant plusieurs représentations vectorielles des contenus.
- GFM (Graph Foundation Models) : ces modèles exploitent la représentation en graphe des connaissances pour mieux comprendre les relations entre entités (personnes, organisations, concepts) et leur contexte. Ils complètent l’approche vecteur en apportant une dimension relationnelle plus explicite.
Selon des spécialistes du domaine, l’intégration des GFM signifie que la qualité des relations entre sources — la réputation, les citations croisées et les liens de confiance — deviendra un facteur aussi important que la pertinence sémantique strictement textuelle pour le classement.
L’association de MUVERA et des GFM représente une évolution vers un référencement davantage centré sur la carte relationnelle du web : au lieu de se contenter d’analyser des mots et des pages isolées, les systèmes évaluent désormais comment les pages s’articulent entre elles, quelles entités elles évoquent, et quelle est la densité et la qualité des interconnexions. Pour le SEO, cela implique plusieurs conséquences pratiques :
- La nécessité d’améliorer l’empreinte relationnelle d’un site : mentions cohérentes, profils d’auteurs clairement identifiables, citations et liens provenant de sources reconnues.
- Une attention renforcée portée à la structuration des données et aux formats permettant d’exprimer les relations (données structurées, schémas d’entités, graphes de connaissances internes).
- L’importance accrue du contenu de référence : études originales, analyses approfondies et ressources qui peuvent être citées par d’autres acteurs.
En résumé, la montée en puissance des approches vectorielles et des modèles en graphe traduit un basculement : le SEO ne se limite plus à l’optimisation de pages isolées, mais engage la construction d’une présence numérique crédible et reliée au reste du web.
Web Guide : une nouvelle forme d’organisation des pages de résultats
Parmi les nouveautés expérimentales, Google a dévoilé Web Guide, une fonctionnalité en cours de test qui modifie la présentation des résultats. Plutôt que d’afficher une liste linéaire de liens, Web Guide regroupe les URL en sections thématiques ou par angle de traitement, afin de faciliter la navigation sur des recherches larges ou complexes. L’outil s’appuie sur une version adaptée de Gemini pour mieux interpréter l’intention de la requête et organiser les ressources en rubriques signifiantes.
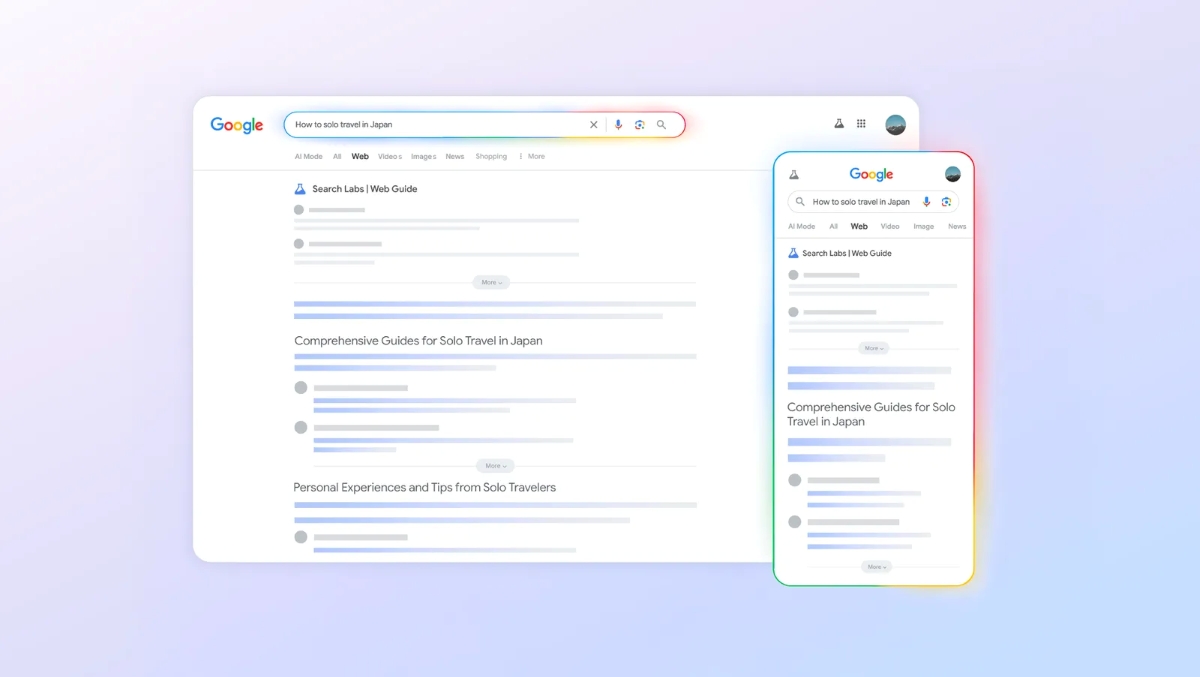
Pour les utilisateurs, Web Guide promet une expérience de recherche plus structurée : regroupements par intention (ex. : « tutoriels », « comparatifs », « actualités »), angles d’approche ou synthèses thématiques. Pour les éditeurs, cette évolution implique d’optimiser non seulement le contenu textuel mais aussi la manière dont il s’inscrit dans un ensemble thématique cohérent : balises Hn claires, liens internes pertinents, et métadonnées qui facilitent l’indexation thématique.
En outre, l’intégration de Gemini dans ce processus souligne la place croissante des modèles de langage avancés dans l’interface utilisateur des moteurs : ces modèles servent désormais à interpréter l’intention et à reformuler ou regrouper l’information au service d’une navigation plus efficace.
L’impact de l’IA sur les parcours de recherche : enseignements d’études récentes
Plusieurs enquêtes publiées cet été documentent l’évolution des comportements de recherche sous l’influence des assistants et moteurs d’IA. L’étude The Rise of AI Search Archetypes (Yext et Researchscape International) met en évidence que les internautes n’utilisent plus systématiquement Google comme premier réflexe. Des alternatives comme ChatGPT, Gemini, TikTok ou Perplexity occupent des places significatives dans le parcours d’information.
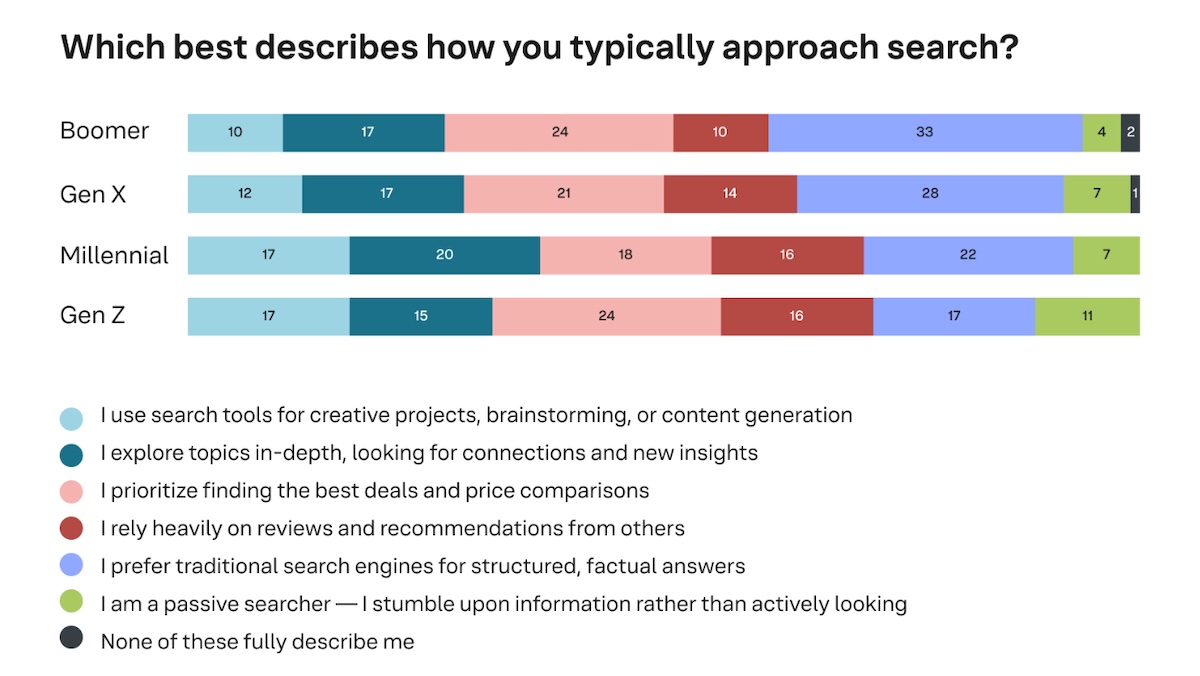
La principale conclusion de cette étude est la segmentation des comportements en « archétypes » d’utilisateurs : profils orientés créativité, exploration, recherche de bonnes affaires, adhérence aux sources traditionnelles, ou navigation accidentelle. Ce découpage signale que les parcours d’accès à l’information deviennent multicanaux et fondés sur l’intention plutôt que sur un unique point d’entrée. Pour les marques et les professionnels du contenu, cela signifie qu’il faut penser une présence adaptée à plusieurs interfaces : résultats classiques, réponses générées par IA, formats courts sur les réseaux sociaux, et plateformes conversationnelles.
Stratégiquement, l’émergence de ces archétypes recommande de diversifier les formats (articles longs, résumés structurés, FAQ, vidéos courtes) et d’adapter le signalement des contenus (données structurées, extraits clairs) pour être éligible à une grande variété d’environnements de diffusion.
Comment Perplexity choisit ses sources : résultats d’une analyse technique
Une étude technique conduite par le chercheur Metehan Yesilyur a apporté des éléments concrets sur le fonctionnement du moteur de réponses Perplexity. L’un des éléments clés mis en lumière est l’usage d’un système de reclassement complexe reposant sur un modèle d’apprentissage à trois couches (L3), particulièrement orienté vers la recherche d’entités (personnes, organisations, concepts spécifiques).
L’analyse montre que Perplexity combine plusieurs types de signaux pour établir la hiérarchie des sources : priorité aux contenus récents, catégorisation thématique, adéquation sémantique, et indicateurs d’engagement. De plus, le moteur applique une curation manuelle partielle en s’appuyant sur des listes de « domaines faisant autorité » qui bénéficient d’un traitement préférentiel. Au total, l’étude recense 59 facteurs influençant directement la visibilité dans les réponses de Perplexity.
Cette méthodologie implique deux enseignements pour les éditeurs : d’une part, la fraîcheur et la qualité éditoriale restent des leviers importants ; d’autre part, figurer dans des listes de sources reconnues, être souvent cité ou repris par des références fiables augmente significativement les chances d’apparaître dans les sorties des moteurs d’IA axés sur la génération de réponses.
Enfin, le cas de Perplexity illustre la diversité des logiques de ranking mises en œuvre par les outils d’IA : contrairement aux moteurs traditionnels qui valorisent majoritairement la pertinence SEO on-page et les signaux de popularité, certains systèmes combinent apprentissage automatique, curation humaine et priorisation temporelle pour produire des réponses synthétiques.
Des résumés automatisés dans Discover et une API pour Google Trends
Plusieurs expérimentations ont été repérées concernant l’usage de l’IA dans les produits grand public. Aux États‑Unis, Google a commencé à déployer des résumés générés par IA au sein de Discover. Après avoir identifié un sujet largement traité par différents médias, Google utilise Gemini pour produire une synthèse des points saillants ; les logos des trois sources dominantes s’affichent en tête du résumé, suivi des liens vers les articles originaux. Des résumés automatiques de vidéos YouTube ont également été observés.
Par ailleurs, la plateforme Google Trends s’est enrichie d’une API, qui est pour l’instant disponible en accès restreint à des testeurs. Cette interface permet d’interroger des données historiques (jusqu’à cinq ans) et d’obtenir des découpages géographiques fins par région et sous‑région. L’arrivée de cette API apporte aux analystes, journalistes et développeurs un accès plus structuré aux tendances de recherche, facilitant la production d’études et d’outils d’analyse.
Dans la perspective des éditeurs, l’intégration de résumés automatisés dans des surfaces comme Discover soulève des enjeux d’attribution et de trafic : si les synthèses réduisent le besoin d’un clic pour obtenir l’essentiel, elles peuvent aussi faire perdre des visites directes. À moyen terme, la qualité des extraits (titres, chapeaux, structure) et l’usage de balises meta optimisées pour le repérage par IA deviendront des éléments déterminants pour maintenir une visibilité effective.
Correspondance limitée entre sources citées par les IA et les pages du top 10
Une étude d’Ahrefs s’est intéressée à l’alignement entre les sources citées par divers systèmes d’IA et les pages présentes dans les top 10 de Google et de Bing. Le résultat est frappant : seules 11 % des sources mentionnées par les IA analysées se retrouvent dans les premières positions classiques des moteurs. L’analyse porte sur quatre assistants majeurs : ChatGPT, Gemini, Copilot et Perplexity.
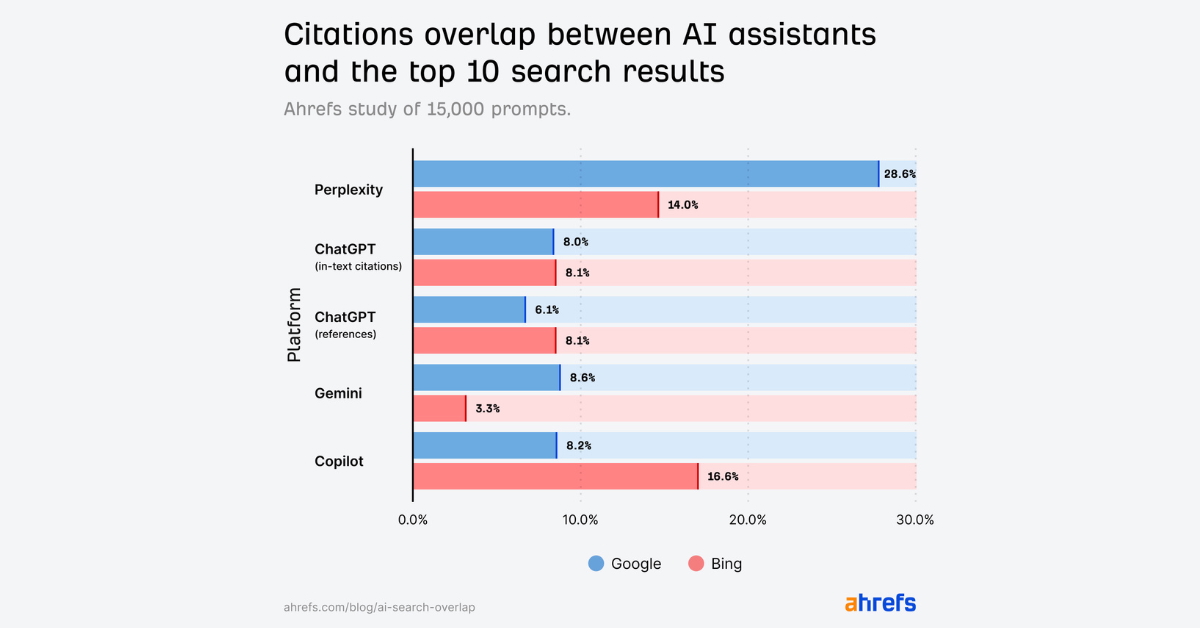
Parmi les résultats notables de l’étude, Perplexity présente le meilleur taux de recoupement avec les pages du top 10, avec environ 28,6 % d’alignement, ce qui s’explique en partie par son orientation à citer explicitement des sources. Copilot montre une corrélation plus marquée avec Bing (environ 16,6 %), tandis que ChatGPT et Gemini affichent des taux plus faibles. Ces divergences proviennent des méthodologies variées : certains outils priorisent la fraîcheur de l’information, d’autres la densité de signaux d’autorité, et d’autres encore l’agrégation de sources multiples sans réconciliation systématique avec les classements des moteurs.
La faible correspondance globale indique que la visibilité dans les réponses d’IA ne se réduit pas automatiquement à une présence dans le top classique des moteurs. Les éditeurs qui souhaitent apparaître à la fois dans les SERP traditionnelles et dans les réponses générées par IA doivent donc adapter simultanément leur stratégie de contenu, leurs signaux de réputation et leur structuration technique pour adresser plusieurs systèmes de ranking aux logiques distinctes.


