Des données récentes montrent que 2 Mo suffisent pour le crawl de Googlebot
La taille du code HTML n'est pas un frein pour 90 % des sites. Explorez comment les données récentes éclairent cette réalité.
Sommaire
- aLes tailles de HTML mobile et desktop se ressemblent
- 1Contrôler le comportement des robots (Tame The Bots)
- 2Outils permettant de connaître le poids d’une page Web
- aOutil Toolsaday pour mesurer la taille d’une page
- bCapture d’écran des résultats Toolsaday
- cSmall SEO Tools : vérificateur de taille de page
- 3Conclusion : pas une préoccupation majeure pour la plupart des sites
- aPourquoi un HTML peut-il devenir très lourd ?
- bSignes indiquant qu’il faut investiguer
- cMesures techniques pour réduire la taille du HTML
- dBonnes pratiques pour la vérification et le suivi
- 4Ressources et utilitaires mentionnés
- aInterpréter les résultats de ces outils
- 5Résumé et perspectives
Lorsque l’on parle d’indexation et d’exploration par les moteurs de recherche, un point revient souvent : la quantité de code HTML qu’un robot peut télécharger avant d’interrompre sa lecture. Dans ce contexte, il est important de comprendre ce que contient réellement un document HTML et si la fameuse limite de 2 Mo imposée par Googlebot est un vrai frein pour la plupart des sites.
Le HTML représente le balisage de la page tel que le lit un crawler : la structure du document, le texte, les balises, et parfois aussi des éléments intégrés en ligne (scripts, styles), qui peuvent rapidement alourdir le fichier. Les liens vers des fichiers externes comme les feuilles de style CSS ou les scripts JavaScript ne sont pas inclus dans la taille du HTML téléchargé, mais les contenus inlines le sont.
Les données récentes publiées par HTTPArchive offrent un éclairage chiffré sur les tailles réelles des HTML rencontrés sur le web. Selon leur dernier rapport, la médiane de la taille brute du HTML observé dans le monde réel est d’environ 33 kilooctets. Au 90e centile, la taille maximale atteint 155 kilooctets, ce qui signifie que pour 90 % des sites, le HTML est inférieur ou environ égal à 155 kilooctets. Ce n’est qu’au 100e centile que la taille du HTML s’envole bien au-delà de deux mégaoctets : les pages dépassant les 2 Mo restent des cas extrêmes, très marginaux.
Le rapport de HTTPArchive précise :
« Les tailles de HTML restent similaires entre les types d’appareils pour les 10e et 25e percentiles. À partir du 50e percentile, le HTML de bureau est légèrement plus volumineux.
Ce n’est qu’au 100e percentile qu’un écart significatif apparaît, le HTML desktop atteignant 401,6 Mo contre 389,2 Mo sur mobile. »
Le jeu de données distingue également la page d’accueil des pages internes et montre, assez étonnamment, que la différence de poids entre ces deux catégories est faible pour la majorité des sites. Le rapport commente :
« Il existe peu d’écart entre la page d’accueil et les pages internes en terme de taille du HTML, cet écart n’étant vraiment notable qu’à partir du 75e percentile.
Au 100e percentile, la différence devient majeure : le HTML des pages internes atteint 624,4 Mo — soit 375 % de plus que le HTML de la page d’accueil, qui atteint 166,5 Mo. »
Les tailles de HTML mobile et desktop se ressemblent
Un constat important est que les tailles de pages entre la version mobile et la version desktop sont remarquablement proches, que l’on considère la page d’accueil ou une page interne. En d’autres termes, la plupart des sites semblent servir le même document HTML aux deux types d’appareils plutôt que de proposer des versions distinctes.
HTTPArchive commente :
« La différence de taille entre mobile et desktop est extrêmement faible, ce qui implique que la majorité des sites renvoient la même page aux utilisateurs mobile et desktop.
Cette stratégie réduit la charge de maintenance pour les développeurs, mais elle peut aussi augmenter le poids de la page global, car deux variantes du site sont en quelque sorte fusionnées dans un seul fichier. »
Même si le poids de la page peut être sensiblement plus élevé lorsque l’on inclut à la fois le contenu destiné au mobile et au desktop dans un seul document, les chiffres observés restent bien en deçà du seuil critique des 2 Mo pour la grande majorité des sites, sauf pour des cas extrêmes.
En tenant compte du fait qu’il faut environ deux millions de caractères pour atteindre les 2 Mo de HTML, et que les données de HTTPArchive montrent que la très grande majorité des pages se situe largement en dessous de cette limite, on peut raisonnablement considérer que la taille du HTML ne doit pas figurer en tête des préoccupations SEO pour la plupart des sites.
Contrôler le comportement des robots (Tame The Bots)
Dans ce contexte, un outil pratique a été développé pour simuler le comportement d’un robot limité par une taille maximale de téléchargement. L’outil Tame The Bots a été mis à jour pour interrompre l’exploration lorsque le texte téléchargé atteint la limite des 2 Mo, ce qui permet d’illustrer visuellement à quel endroit du document Googlebot s’arrêterait pour des pages particulièrement volumineuses.
Dave Smart a expliqué le fonctionnement de cet ajout : il a intégré une fonctionnalité qui plafonne les fichiers textuels à 2 Mo afin de simuler la contrainte de Googlebot. Il a précisé que, bien que ce scénario soit très rare dans la pratique (probablement pour 99,99 % des sites, l’impact est négligeable), cette simulation peut aider à détecter les cas limites.
Voici une capture d’écran de l’interface de Tame The Bots :
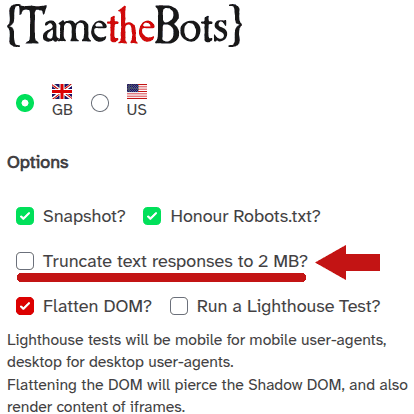
L’outil montre ce que verrait Googlebot si l’exploration s’arrêtait au seuil des 2 Mo. Il ne calcule pas la taille totale du HTML ni n’indique explicitement si la page dépasse la limite ; il sert plutôt à visualiser la portion de document réellement explorée en cas d’arrêt forcé du crawl. Pour obtenir la taille exacte d’une page, d’autres utilitaires spécifiques sont plus adaptés.
Outils permettant de connaître le poids d’une page Web
Plusieurs services en ligne permettent de mesurer le poids de la page ou la taille du HTML. Voici deux outils couramment utilisés pour obtenir un chiffrage rapide et comparer les résultats. Les valeurs peuvent varier légèrement d’un outil à l’autre (quelques kilo-octets d’écart).
Outil Toolsaday pour mesurer la taille d’une page
Le vérificateur de taille de page proposé par Toolsaday est conçu pour tester une URL à la fois. Il fournit une lecture simple du poids d’une page, généralement exprimé en kilo-octets. Ce type d’outil est utile pour un contrôle ponctuel et rapide lorsqu’on souhaite savoir si un document s’approche du seuil critique.
Capture d’écran des résultats Toolsaday
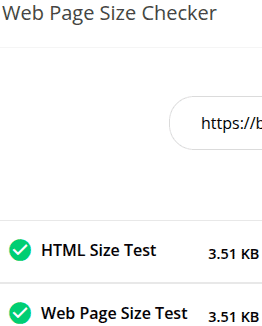
Small SEO Tools : vérificateur de taille de page
Le Small SEO Tools Website Page Size Checker propose une variante intéressante : il permet d’analyser jusqu’à dix URL à la fois, ce qui facilite les contrôles en lot. Cet outil donne une estimation de la taille totale chargée pour une page donnée, incluant souvent le HTML, les images et les ressources externes selon la configuration de l’outil.
Conclusion : pas une préoccupation majeure pour la plupart des sites
Au final, la contrainte d’un plafond de téléchargement de 2 Mo par Googlebot est rarement un problème concret pour les sites Web standards. Les données de HTTPArchive montrent que la majorité des pages ont un HTML bien inférieur à ce seuil, et seuls des cas très particuliers — pages internes avec des montages massifs en ligne, erreurs de construction de templates ou sites avec beaucoup de contenu incrusté inutilement — risquent d’atteindre ce type de limites.
Cependant, il reste utile de savoir comment diagnostiquer et corriger les situations où le HTML devient anormalement volumineux. Voici des précisions pratiques et des recommandations techniques, présentées de manière factuelle, pour les équipes techniques ou les responsables SEO confrontés à des pages très lourdes.
Pourquoi un HTML peut-il devenir très lourd ?
Plusieurs facteurs techniques peuvent conduire à un HTML gonflé :
Templates mal optimisés qui injectent du contenu répétitif sur de nombreuses pages.
Fragments de code ou commentaires de développement laissés en production.
Inclusion massive de scripts et de styles en ligne (inline CSS ou inline JS), plutôt que via des fichiers externes minifiés.
Contenu embarqué volumineux directement dans le HTML (par ex. longs JSON inline, blocs de données, ou images encodées en base64).
Double versionnement des composants pour mobile et desktop fusionné dans un seul document.
Signes indiquant qu’il faut investiguer
Les indicateurs suivants peuvent justifier une analyse approfondie :
Pages qui mettent beaucoup de temps à se charger même en l’absence d’éléments médias lourds.
Logs d’exploration montrant des URLs fréquemment incomplètement indexées ou interrompues.
Mesures d’outils de diagnostic révélant un poids de la page inhabituellement élevé pour le HTML.
Comparaison entre pages similaires montrant des variations fortes au niveau du HTML (par ex. une version interne très plus lourde que la page d’accueil).
Mesures techniques pour réduire la taille du HTML
Si une page s’avère être un cas limite, plusieurs approches techniques peuvent limiter la taille du HTML, sans toutefois altérer la qualité du contenu :
Externaliser les scripts et les styles : extraire le JS et le CSS inline vers des fichiers externes minifiés et compressés.
Éviter l’encodage d’images en base64 dans le HTML — privilégier des ressources externes optimisées.
Supprimer les commentaires et le code mort avant mise en production.
Utiliser la pagination ou le chargement asynchrone pour les données volumineuses (par ex. remplacer de longs JSON inline par des requêtes AJAX).
Appliquer une minification du HTML côté serveur pour retirer les espaces et retours à la ligne inutiles.
Activer la compression côté serveur (gzip ou Brotli) pour réduire le volume transféré.
Revoir les templates pour éviter la duplication de blocs destinés à des variantes mobile et desktop dans une même page.
Bonnes pratiques pour la vérification et le suivi
Pendant l’audit et la phase de correction, il est pertinent d’appliquer ces étapes systématiques :
Mesurer la taille du HTML avant et après chaque modification via des outils fiables.
Comparer les résultats entre environnements de développement et de production pour détecter les divergences.
Documenter les modifications apportées au template pour identifier rapidement les sources de régression.
Surveiller les logs d’exploration pour vérifier qu’aucune URL critique n’est tronquée lors du crawl.
Maintenir une bonne communication entre équipes de développement et SEO pour prioriser les corrections selon l’impact sur l’indexation.
Ressources et utilitaires mentionnés
Plusieurs ressources et outils peuvent aider à obtenir des mesures et simulations utiles :
HTTPArchive — source de données agrégées sur les caractéristiques du web moderne (taille du HTML, composition des pages, etc.).
Tame The Bots — simulateur qui coupe l’exploration à 2 Mo pour illustrer le point d’arrêt d’un robot.
Le post de Dave Smart sur la mise à jour de l’outil, accessible via son compte public (historique de la modification).
Toolsaday — vérificateur de taille d’URL (analyse une page à la fois).
Small SEO Tools — vérificateur qui permet d’analyser plusieurs URLs par lot.
Interpréter les résultats de ces outils
Chaque utilitaire a sa logique et ses limites : certains calculent la taille du seul HTML, d’autres estiment le poids total des ressources sollicitées pour afficher la page. Il est donc conseillé d’interpréter les chiffres selon le périmètre de l’outil :
Un test mesurant uniquement le HTML est pertinent pour savoir si le document envoyé par le serveur pourrait atteindre la limite physique de Googlebot.
Un test mesurant le poids total de la page (images, scripts, CSS externes) donne une vision utile pour les performances visibles par l’utilisateur, mais ne correspond pas exactement à la limite d’exploration basée sur le HTML.
Des écarts mineurs entre outils (quelques kilo-octets) sont normaux ; des différences importantes doivent attirer l’attention et justifier une vérification plus approfondie.
Résumé et perspectives
Pour synthétiser :
La majorité des sites web ont un HTML nettement inférieur à la limite des 2 Mo et ne sont donc pas impactés par ce seuil au niveau de l’exploration par Googlebot.
Les mesures historiques de HTTPArchive montrent que seuls des cas marginalement rares dépassent ce seuil de manière significative.
Cependant, pour les sites très volumineux ou mal architecturés, la taille du HTML peut devenir un facteur limitant ; dans ce cas, des mesures d’optimisation ciblées peuvent réduire le risque d’arrêt du crawl.
En pratique, il est recommandé de traiter la taille du HTML comme un indicateur parmi d’autres : surveiller régulièrement les métriques, identifier les anomalies et collaborer avec les équipes techniques pour corriger les sources d’embonpoint lorsque cela s’avère nécessaire. Les outils évoqués — dont Tame The Bots, Toolsaday et Small SEO Tools — servent d’outils de diagnostic complémentaires pour éclairer ces investigations.


