La recherche vocale de Google gagne en fiabilité grâce au S2R
Google remplace le schéma « parole → texte → recherche » par un modèle capable de rechercher directement depuis l’oral, sans passer …
Sommaire
- 1Points essentiels à retenir :
- 2Pourquoi Google modifie radicalement la chaîne voix→recherche maintenant
- 3Performances : au‑delà de l’ASR, proches du plafond théorique
- 4Conséquences pour l’expérience des utilisateurs
- 5Impacts SEO et marketing à prévoir
- 6Rôle et portée de SVQ et du benchmark MSEB
- 7Cas pratique : pourquoi « the scream painting » illustre bien le changement
- 8Limites actuelles et perspectives d’évolution
- 9Conséquences techniques pour les équipes d’ingénierie et produits
- 10Recommandations pratiques pour les créateurs de contenu
- 11Considérations éthiques et vie privée
- 12Quel avenir pour la recherche vocale et l’accès à l’information
- 13En résumé
- aArticles connexes
Google remplace le schéma « parole → texte → recherche » par un modèle capable de rechercher directement depuis l’oral, sans passer par une transcription intermédiaire, afin d’obtenir des réponses plus rapides et mieux alignées sur l’intention. Cette approche est déjà déployée dans plusieurs langues. Sous le capot, Google associe la requête vocale aux contenus les plus pertinents puis laisse son moteur de classement hiérarchiser les résultats, et s’appuie sur un jeu de tests ouvert pour mesurer objectivement les progrès.
Points essentiels à retenir :
- S2R court-circuite la chaîne traditionnelle ASR : la requête orale est transformée en vecteur sémantique et mise en correspondance directe avec les documents, ce qui réduit les erreurs issues d’une transcription intermédiaire.
- Les résultats montrent que S2R dépasse le pipeline Cascade ASR et se rapproche de l’« upper bound » (transcriptions humaines) sur la métrique MRR, signe d’un gain réel en pertinence.
- Le système est opérationnel dans plusieurs langues et combine la similarité sémantique avec des centaines de signaux de qualité dans la phase de ranking.
- Google publie le dataset SVQ (17 langues, 26 locales) au sein du benchmark MSEB pour encourager la recherche et la reproductibilité.
Pourquoi Google modifie radicalement la chaîne voix→recherche maintenant
Jusqu’ici, la technique la plus répandue consistait à utiliser un moteur de reconnaissance vocale — la cascade ASR — qui convertit l’audio en texte avant d’effectuer une recherche textuelle classique. Ce processus est sensible : une seule erreur de transcription (par exemple « scream » interprété comme « screen ») peut dévier complètement l’intention et produire des résultats hors sujet. La proposition de Speech‑to‑Retrieval (S2R) renverse la question : au lieu de se demander « quels mots ont été prononcés ? », l’objectif devient « quelle information cherche l’utilisateur ? ». Cette perspective réduit fortement l’effet domino des erreurs de reconnaissance.
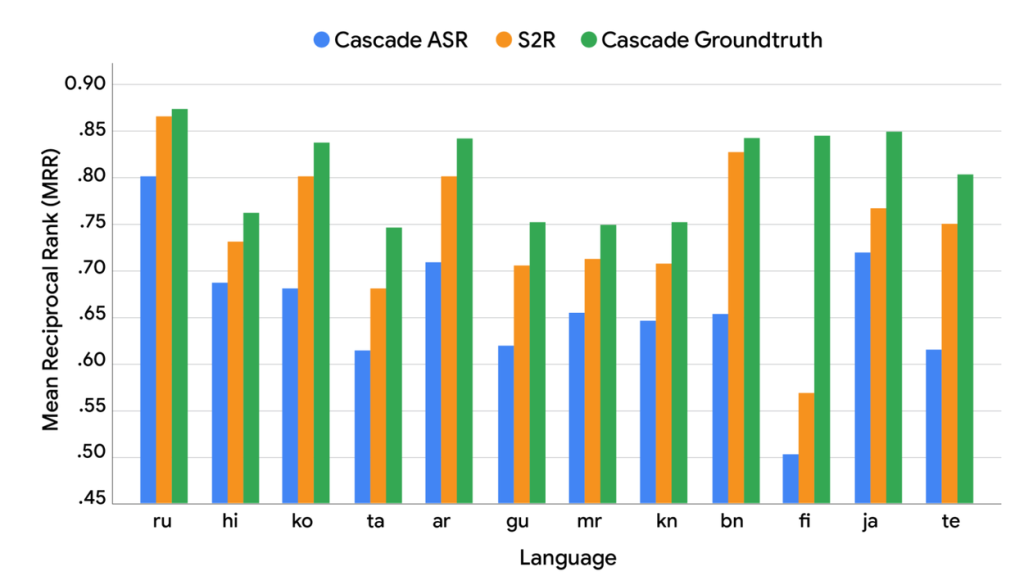
Les ingénieurs ont mis en parallèle plusieurs configurations : un pipeline Cascade ASR classique, une version « groundtruth » basée sur des transcriptions humaines parfaites, et le modèle S2R. Les résultats montrent qu’un ASR impeccable n’implique pas nécessairement la meilleure pertinence des réponses (mesurée en MRR). Cet enseignement explique pourquoi il est pertinent d’optimiser directement pour l’intention exprimée dans l’audio plutôt que pour la fidélité mot-à-mot de la transcription.
Au cœur de S2R se trouve un mécanisme de type dual‑encoder : un encodeur dédié à l’audio qui transforme la requête vocale en un embedding audio dense et sémantique, et un second encodeur qui projette les documents (pages web, articles, etc.) dans le même espace vectoriel. L’entraînement vise à rapprocher géométriquement les vecteurs des paires audio‑document pertinentes et à éloigner ceux sans rapport.
En production, l’embedding audio sert à effectuer un rappel rapide de candidats dans l’index, puis une étape de ranking intervient pour ordonner ces candidats en combinant la similarité sémantique et des centaines de signaux classiques du moteur de recherche. Cette intégration permet de conserver des temps de réponse compétitifs tout en améliorant la pertinence finale affichée à l’utilisateur.
Performances : au‑delà de l’ASR, proches du plafond théorique
Sur le dataset SVQ (Simple Voice Questions), S2R surpasse nettement la chaîne Cascade ASR en termes de MRR et se rapproche de l’« upper bound » obtenu avec des transcriptions humaines (« groundtruth »). Ces gains apparaissent pour plusieurs langues, ce qui indique une amélioration robuste et généralisable de la pertinence des résultats issus d’une requête vocale.
Un enseignement important de ces expérimentations est la dissociation entre la simple réduction des erreurs de mots (mesurée par le WER) et l’amélioration effective de la pertinence de recherche (mesurée par le MRR). Autrement dit, diminuer le WER n’entraîne pas mécaniquement une hausse proportionnelle du MRR : l’impact dépend de la nature des erreurs (mots-clés manquants, substitutions critiques, variabilité linguistique) et du contexte. D’où l’intérêt stratégique d’optimiser la compréhension d’intention directement à partir de l’audio.
Conséquences pour l’expérience des utilisateurs
- Réduction des interprétations erronées : les requêtes ambigües, formulées de manière approximative ou prononcées dans un contexte bruyant sont mieux traitées, car la logique repose davantage sur la similarité sémantique que sur la correspondance exacte de mots. Par exemple, une phrase maladroite parlant d’une « peinture qui crie » pourra aboutir correctement à l’œuvre « The Scream » plutôt qu’à des pages sur les écrans (« screen »).
- Réponses plus rapides : en éliminant la nécessité d’une transcription parfaitement fidèle avant la recherche, le système évite une étape coûteuse et fragile, tout en gardant l’étage de classement existant. L’utilisateur bénéficie d’une perception de pertinence plus « intelligente » et d’un temps d’attente réduit.
- Couverture multilingue dès le départ : la solution est déjà active sur plusieurs langues, ce qui améliore l’efficacité sur des requêtes non anglaises et dans des contextes où l’ASR avait des limites. Ce progrès reflète les choix d’entraînement et d’évaluation effectués avec le dataset SVQ.
Impacts SEO et marketing à prévoir
La généralisation d’un flux de recherche basé sur la mise en correspondance sémantique audio→document modifie la nature de l’optimisation. Trois axes principaux méritent l’attention des responsables de contenu et des équipes SEO :
- Évolution du matching : du lexical vers le sémantique — L’accent se déplace de la simple optimisation pour des mots-clés précis vers la capacité d’un contenu à répondre clairement à une intention exprimée de nombreuses façons. La structure du contenu, la hiérarchie des réponses, la présence d’exemples et de paraphrases deviennent cruciaux. En pratique, cela signifie produire des pages qui répondent explicitement à des questions et variantes formulaires, plutôt que d’aligner mécaniquement des occurrences de mots exacts.
- Renforcement des signaux de qualité dans le ranking final — Même si S2R fournit un rappel sémantique pertinent, le classement final repose toujours sur un ensemble riche de signaux (autorité, E‑E‑A‑T, expérience utilisateur, fraîcheur, performances techniques). Les pratiques SEO classiques restent donc indispensables : contenu fiable, structure claire, balisage sémantique et optimisation technique continuent d’influencer fortement la position finale.
- Importance accrue de la clarté sémantique multilingue — Dans des marchés à forte variabilité linguistique ou sujets au code‑switching, la rédaction doit intégrer des mécanismes de désambiguïsation (glossaires, sections FAQ, encadrés de définition, entités nommées) pour aider le modèle à relier l’intention audio aux éléments de réponse pertinents. La cohérence sémantique et le maillage interne deviennent des leviers importants.
Autre implication : les formulations conversationnelles et les phrases familières doivent être anticipées. Le contenu qui offre des réponses courtes et explicites, ainsi que des variantes phraseologiques au sein d’un même document, augmentera sa probabilité d’être rappelé par une embedding audio proche. Enfin, les tests et l’analyse des logs vocaux (dans le respect de la vie privée) permettront de détecter les formulations récurrentes et d’adapter les contenus.
Rôle et portée de SVQ et du benchmark MSEB
Pour favoriser la recherche ouverte, Google a publié le dataset Simple Voice Questions (SVQ) sur la plateforme Hugging Face. Ce corpus contient des courtes questions audio en 17 langues et 26 locales, enregistrées dans des conditions variées (audio propre, bruit de fond, circulation, émissions), afin d’offrir une base d’évaluation standardisée pour l’alignement audio→document. SVQ s’intègre dans le cadre plus large du Massive Sound Embedding Benchmark (MSEB), qui vise à comparer et mesurer les approches d’indexation et de recherche basées sur des embeddings audio.
La mise à disposition de ce jeu de données poursuit plusieurs objectifs : encourager la reproductibilité scientifique, permettre des comparaisons objectives entre méthodes et fournir un référentiel pour évaluer l’impact réel de nouvelles architectures sur la pertinence utilisateur, au‑delà des métriques classiques d’ASR. En somme, SVQ et MSEB offrent à la communauté un cadre pour mesurer des progrès comparables dans le temps.
Cas pratique : pourquoi « the scream painting » illustre bien le changement
Dans un pipeline Cascade ASR, une substitution de mot comme « screen » à la place de « scream » produit des résultats erronés : l’utilisateur obtient des pages sur les écrans au lieu d’informations sur le tableau de Munch. Avec S2R, la requête orale est projetée dans un espace sémantique où des entités telles que « The Scream », « Edvard Munch » ou « Munch Museum » sont naturellement proches du vecteur audio généré. Le module de ranking applique ensuite des critères de qualité pour ordonner ces documents.
Ce scénario met en lumière deux propriétés essentielles : la tolérance aux paraphrases et aux imprécisions phonétiques, et la capacité du système à retrouver des documents pertinents même lorsque les mots exacts ne sont pas reproduits à l’identique. C’est précisément ce que promet l’approche audio→document : une correspondance basée sur l’intention plutôt que sur la littéralité des termes.
Limites actuelles et perspectives d’évolution
Malgré des progrès notables, plusieurs défis subsistent. Le modèle atteint une proximité avec le « groundtruth », mais un écart persiste, laissant place à des optimisations futures. Parmi les limites identifiées :
- Alignement fin audio↔document : il reste à mieux calibrer la concordance entre certaines formulations orales et les documents, notamment pour des requêtes très spécifiques ou légères en termes de signaux sémantiques.
- Code‑switching et mélange de langues : les requêtes comportant un changement de langue au sein d’une même phrase (code‑switching) posent encore des difficultés. Le modèle doit améliorer sa robustesse aux mélanges linguistiques et aux variations dialectales.
- Environnements très bruyants : si l’approche sémantique augmente la tolérance au bruit, il existe toujours des conditions acoustiques extrêmes où l’information utile est trop dégradée pour permettre un rappel fiable.
Sur le plan produit, des questions d’UX restent ouvertes : faut‑il afficher une paraphrase textuelle de la requête détectée, comment montrer à l’utilisateur la confiance du système, ou encore comment permettre un contrôle si la recherche orale a mal interprété l’intention ? Ces choix affecteront l’acceptation et la confiance de l’utilisateur, mais n’invalident pas la pertinence technique démontrée par la combinaison retrieval + ranking aujourd’hui en production.
Les prochaines étapes probables incluent un raffinement des représentations audio, l’augmentation des données d’entraînement multiculturelles, des travaux sur les métriques qui reflètent mieux l’expérience utilisateur réelle, et des améliorations pour la gestion des dialogues et du contexte conversationnel prolongé.
Conséquences techniques pour les équipes d’ingénierie et produits
Pour les équipes techniques, l’adoption d’un paradigm audio→document implique plusieurs évolutions architecturales et opérationnelles :
- Mise en place et gestion d’index vectoriels : l’utilisation d’embeddings impose des solutions d’indexation de vecteurs à grande échelle (FAISS, ScaNN, HNSW++ ou alternatives commerciales), capables de rappeler rapidement des candidats pertinents parmi des milliards de documents.
- Pipeline hybride retrieval + ranking : le pipeline doit maintenir un équilibre entre rappel sémantique (rapide) et classement multi‑signal (plus lent mais plus précis). Cela nécessite une orchestration fine, des caches efficaces et des métriques de latence strictes.
- Surveillance et métriques opérationnelles : au-delà du WER, il faut suivre des métriques orientées utilisateur comme la MRR, le taux de satisfaction mesuré par tests, et des signaux qualitatifs extraits des logs (avec respect de la confidentialité). Des jeux de tests spécialisés, comme SVQ, aident à monitorer les régressions.
- Gestion du modèle et mises à jour : l’entraînement d’encodeurs audio et texte, leur quantification, déploiement et rafraîchissement d’index exigent des process robustes pour éviter les dérives et assurer une expérience stable.
Recommandations pratiques pour les créateurs de contenu
Du côté contenu, plusieurs bonnes pratiques émergent naturellement pour rester visible et pertinent dans un environnement où l’oral peut interroger directement le contenu :
- Réponses claires et structurées : favorisez des sections Q&R, des introductions synthétiques, des résumés et des réponses directes à des questions fréquemment posées. Les modèles sémantiques privilégient les contenus qui exposent explícitement l’intention.
- Variation phrastique : intégrez des reformulations et synonymes naturels dans vos textes afin d’augmenter la probabilité qu’un fragment corresponde à une représentation audio donnée.
- Désambiguïsation explicite : utilisez des encadrés, glossaires et définitions pour expliciter les sens possibles d’un terme, afin d’aider le système à choisir la bonne entité quand une requête orale est ambiguë.
- Rich media et balisage sémantique : microdonnées, titres clairs, sous-titres et alternatives textuelles renforcent la compréhension du document par les algorithmes de ranking.
- Multilinguisme maîtrisé : pour les sites en plusieurs langues, assurez une séparation claire des contenus par locale et fournissez des équivalences textuelles et contextuelles pour faciliter l’alignement audio→document.
Considérations éthiques et vie privée
L’utilisation accrue de requêtes vocales soulève des questions liées à la confidentialité et à l’éthique. Les organisations doivent s’assurer que les traitements audio respectent les réglementations (consentement, anonymisation, conservation limitée). Par ailleurs, la collecte de données vocales pour améliorer les modèles doit être transparente et assortie de garanties : minimisation, sécurité et possibilité pour l’utilisateur de refuser la collecte ou d’effacer ses enregistrements.
Sur le plan algorithmique, il est également nécessaire de surveiller les biais linguistiques : si les datasets d’entraînement sous‑représentent certaines minorités linguistiques, l’alignement audio↔document pourrait se dégrader pour ces populations. La publication de datasets open comme SVQ vise précisément à encourager la diversité et la reproductibilité, mais des efforts supplémentaires seront nécessaires pour garantir l’équité.
Quel avenir pour la recherche vocale et l’accès à l’information
L’émergence de modèles capables de rechercher directement depuis l’audio transforme la manière dont les utilisateurs interagissent avec l’information. On peut envisager plusieurs évolutions :
- Interfaces conversationnelles plus naturelles : la recherche pourrait intégrer davantage de dialogues continus et contextuels, où plusieurs tours de question/réponse affinent l’intention sans reposer sur des transcriptions exhaustives.
- Accès facilité pour des publics variés : l’amélioration de la robustesse aux accents, aux langues régionales et au bruit rendra la recherche vocale plus inclusive, notamment pour les utilisateurs ayant des difficultés à taper ou préférant l’oral.
- Nouvel écosystème d’outils SEO : des solutions d’audit, de test et d’optimisation spécifiques à l’audio→document devraient apparaître pour aider les éditeurs à mesurer leur visibilité dans ce nouveau flux.
En résumé
L’approche Speech‑to‑Retrieval (S2R) marque un changement de paradigme : plutôt que de transcrire d’abord puis chercher, Google projette directement l’audio dans un espace sémantique commun aux documents pour rappeler des candidats pertinents, avant d’appliquer un ranking riche en signaux. Cette méthode réduit la propagation des erreurs liées à la transcription, améliore la pertinence mesurée (notamment en MRR) et est déjà utilisée en production sur plusieurs langues. La publication du dataset SVQ dans MSEB offre un cadre ouvert pour évaluer et comparer les approches.
Pour les praticiens, cela implique de privilégier la clarté d’intention, la structure sémantique, la qualité éditoriale et la robustesse multilingue. Sur le plan technique, il faudra investir dans des index vectoriels, des pipelines hybrides retrieval/ranking et des métriques centrées sur l’expérience utilisateur. Enfin, le respect de la vie privée et la lutte contre les biais restent des impératifs au fur et à mesure que la recherche vocale se généralise.


