L’outil de Google pour les sources recommandées est envahi par le spam
La fonctionnalité Preferred Sources de Google a été conçue pour permettre aux lecteurs de privilégier certains sites d’information et d’en …
Sommaire
- 1Présentation de Google Preferred Sources
- 2Des domaines très similaires s’invitent dans Preferred Sources
- aCapture d’écran : sous-domaine aléatoire apparaissant pour Automattic
- 3Des erreurs ou des lacunes dans la sélection des sources
- aCapture d’écran : domaine indien parké
- bCapture d’écran : domaine NYTimes indien parké
- cCapture d’écran : HuffPost apparaissant dans les préférences de source
- dCapture d’écran : résultat d’une recherche site:
- eCapture d’écran : SEJ dans l’outil de préférences de sources
- 4Quelles explications possibles ?
- 5Impacts pour les utilisateurs et les éditeurs
- 6Mesures possibles pour corriger la situation
- aPour Google
- bPour les éditeurs / propriétaires de marques
- cPour les utilisateurs
- 7Pourquoi certains domaines n’ont que la page d’accueil indexée ?
- 8Aspects juridiques et de marque
- 9Considérations techniques pour la détection automatique
- 10Observations finales
- aArticles connexes
La fonctionnalité Preferred Sources de Google a été conçue pour permettre aux lecteurs de privilégier certains sites d’information et d’en retrouver davantage dans la section Top Stories. Or, depuis son déploiement, des domaines copie conforme, des sites de faible qualité et même des noms de domaine parkés apparaissent dans cette liste. Plusieurs de ces sites sont tellement rudimentaires que seule leur page d’accueil est indexée. Ne devrait-on pas s’attendre à ce que cet outil ne montre que des sites authentiques et fiables, et non des plateformes de spam ou d’usurpation ?
Présentation de Google Preferred Sources
La fonctionnalité Preferred Sources vise à offrir une couche de personnalisation supplémentaire aux utilisateurs en leur permettant d’indiquer quelles sources d’information ils souhaitent voir priorisées dans les résultats de type Top Stories. Plutôt que de s’en remettre uniquement aux algorithmes de classement de Google, l’internaute peut ainsi orienter l’affichage vers des médias qu’il préfère. Il est important de souligner que ce mécanisme ne bloque pas l’affichage d’autres sites : il personnalise l’expérience en favorisant les sources sélectionnées pour cet utilisateur.
Concrètement, l’objectif affiché est d’augmenter la pertinence perçue par l’utilisateur en tenant compte de ses préférences déclarées, sans pour autant modifier la disponibilité générale des résultats pour les autres internautes. Toutefois, dans la pratique, l’outil semble parfois lister des domaines qui ne correspondent pas au niveau de qualité attendu d’un média d’information reconnu.
Des domaines très similaires s’invitent dans Preferred Sources
Une tendance constatée est l’enregistrement de domaines très proches de ceux de sites connus. Cette pratique prend souvent la forme de domain squatting : des acteurs enregistrent des variantes d’un nom de domaine en changeant l’extension (TLD) ou en ajoutant un préfixe, ce qui crée des adresses trompeuses. Par exemple, lorsqu’un nom de domaine renommé existe en .com ou .net, des enregistrements identiques peuvent être créés en .com.in ou .net.in, donnant l’illusion d’une déclinaison locale ou officielle.
Ces domaines imitent généralement l’apparence d’un site légitime ou utilisent des intitulés proches pour profiter de la reconnaissance d’une marque et attirer du trafic, parfois uniquement pour monétiser des clics ou proposer des contenus très restrictifs. Dans certains cas, il s’agit d’adresses qui redirigent vers des pages de publicité, des offres financières douteuses ou des pages à contenu mince, ce qui pose un problème de qualité dans la sélection des sources.
Capture d’écran : sous-domaine aléatoire apparaissant pour Automattic
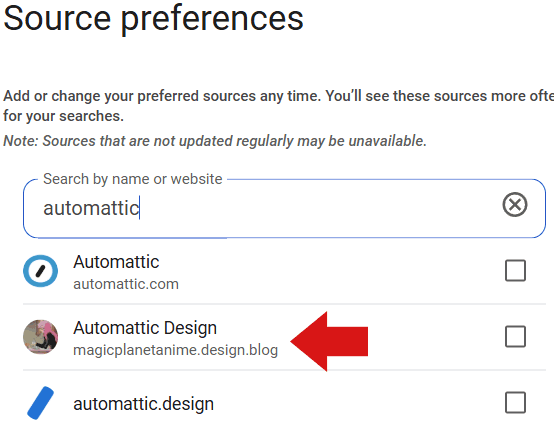
Des erreurs ou des lacunes dans la sélection des sources
Il n’est pas encore clair si ces domaines sont ajoutés manuellement au sein de l’outil Preferred Sources par des individus malveillants, ou s’ils sont découverts automatiquement par les systèmes de Google et proposés aux utilisateurs. Une recherche portant sur un outil SEO populaire retourne bien le domaine attendu, mais également un domaine parké enregistré sous le ccTLD indien .com.in, ce qui laisse penser que le filtre de qualité n’est pas toujours appliqué de manière cohérente.
Capture d’écran : domaine indien parké
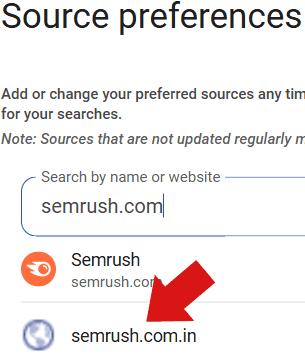
Le phénomène observé est double : d’une part des copies de noms de domaines sont enregistrées dans des TLD locaux, d’autre part certains de ces domaines n’hébergent qu’une page d’accueil sans contenu éditorial substantiel. Ces sites peuvent néanmoins être visibles dans la liste des Preferred Sources, ce qui interroge sur les critères d’admission utilisés par Google.
Il est avéré que des acteurs enregistrent des domaines copycat, mais le parcours exact qui conduit ces domaines à figurer dans l’outil reste flou. À l’heure actuelle, la fonctionnalité est disponible aux États-Unis et en Inde ; cette disponibilité géographique peut expliquer la présence disproportionnée de domaines indiens dans les résultats.
Capture d’écran : domaine NYTimes indien parké
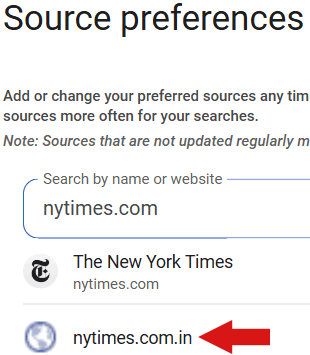
Par exemple, une recherche du nom d’un média connu dans l’outil montre parfois une version régionale ou un domaine apparenté enregistré en Inde. Ces sites “indien” affichent des contenus qui n’ont souvent aucun rapport éditorial avec la marque qu’ils imitent — on y trouve par exemple des articles liés aux prêts sur salaire, des liens vers des avocats en dommages corporels ou des publicités pour des montres de luxe — et il semble que l’indexation par Google se limite fréquemment à la page d’accueil.
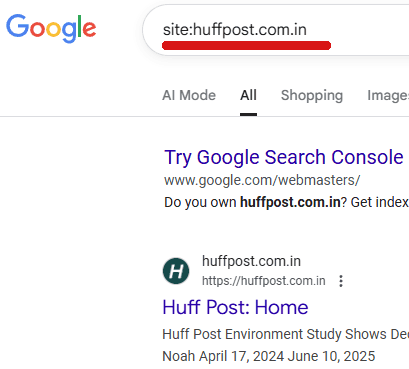
Capture d’écran : HuffPost apparaissant dans les préférences de source
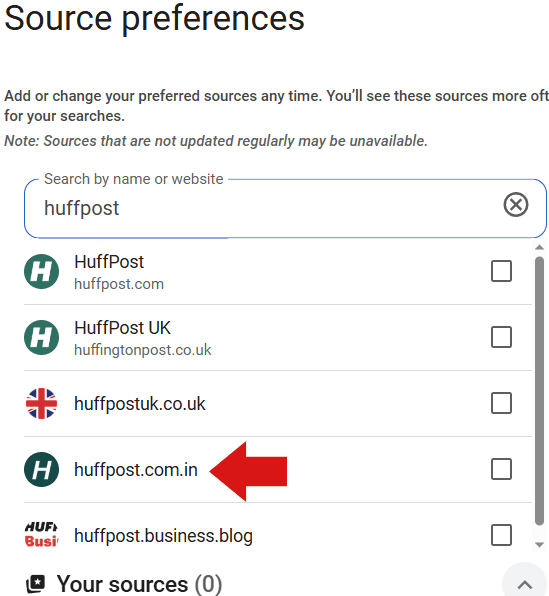
La version indienne identifiée du HuffPost propose des liens et des rubriques qui ne correspondent pas au profil d’un média d’actualité sérieux. Les pages internes ne semblent pas indexées, ce qui suggère qu’il s’agit davantage d’un site-masse publicitaire ou d’un domaine monopage que d’une édition locale légitime. Ce type d’apparition fausse la perception de la qualité des sources proposées dans l’outil.
Capture d’écran : résultat d’une recherche site:
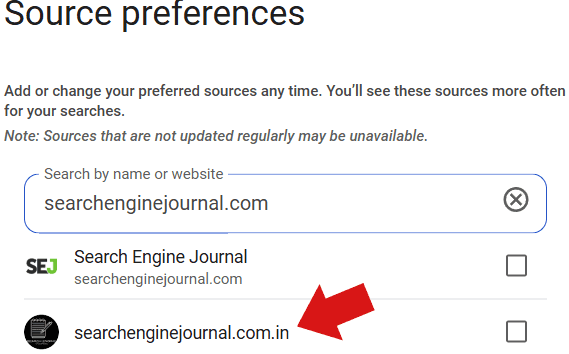
Un autre exemple : un domaine indien squatteur du nom de domaine de Search Engine Journal.
Capture d’écran : SEJ dans l’outil de préférences de sources
Quelles explications possibles ?
Plusieurs scénarios peuvent expliquer la présence de ces domaines dans la fonctionnalité Preferred Sources :
- Soumission manuelle : des individus — parfois des spécialistes du SEO ou des acteurs opportunistes — peuvent enregistrer des domaines copiés et les soumettre directement via l’interface de préférences, en espérant capter des utilisateurs qui sélectionnent ces variantes.
- Découverte automatique : les systèmes automatiques de détection et d’indexation de Google pourraient identifier ces domaines comme des sources potentielles et les proposer sans contrôle humain approfondi.
- Erreurs de désambiguïsation : un mécanisme de correspondance de noms insuffisamment strict peut associer des variantes locales d’un nom de marque à l’original sans vérification de propriété.
- Disponibilité géographique : parce que l’outil est activé dans certains pays (notamment les États-Unis et l’Inde), les ccTLD locaux apparaissent davantage dans ces régions, donnant l’impression d’une présence accrue de domaines indiens.
Quel que soit le mécanisme exact, l’effet est le même : des sites de faible qualité ou des enregistrements trompeurs peuvent être proposés aux utilisateurs comme « sources préférées », ce qui dégrade la confiance dans le mécanisme de personnalisation.
Impacts pour les utilisateurs et les éditeurs
La visibilité de domaines douteux dans Preferred Sources comporte plusieurs conséquences :
- Expérience utilisateur dégradée : les lecteurs qui choisissent des sources en croyant sélectionner un média reconnu peuvent se retrouver dirigés vers des pages sans contenu pertinent ou à vocation publicitaire.
- Risque de désinformation : lorsque des domaines imitants publient des contenus mensongers ou non vérifiés, ils peuvent disséminer de la désinformation sous une apparence de légitimité.
- Atteinte à la marque : les médias légitimes voient leur nom usurpé, ce qui peut nuire à leur image et à la confiance des lecteurs.
- Distorsion des signaux SEO : des domaines parcés ou avec peu de contenu peuvent influencer la perception algorithmique de la qualité d’une source si ces signaux ne sont pas filtrés correctement.
Pour les éditeurs, l’apparition de variantes frauduleuses de leur nom de domaine représente une menace commerciale et éditoriale : perte de trafic, dilution de l’autorité et coûts liés à la surveillance et à la protection de la marque.
Mesures possibles pour corriger la situation
Plusieurs actions peuvent aider à réduire l’impact de ces pratiques et à améliorer la qualité des sources proposées :
Pour Google
- Vérification de propriété : exiger la preuve de propriété (par exemple via Google Search Console) avant d’autoriser un domaine à figurer comme source privilégiée. Un mécanisme d’authentification réduirait l’ajout de domaines copiés par des tiers.
- Filtrage des domaines parkés et des pages monopages : implémenter des contrôles qui détectent les domaines sans contenu éditorial substantiel (faible profondeur d’indexation, pages redondantes) et les excluent automatiquement de la liste.
- Amélioration de la détection des imitation de marques : utiliser des algorithmes de détection de similarité de nom et de signalement automatique des domaines imitant une marque connue pour examen humain ou restriction.
- Transparence et signalement : fournir un canal clair pour que les éditeurs légitimes signalent des domaines usurpateurs détectés dans l’outil, avec des délais de traitement publics.
Pour les éditeurs / propriétaires de marques
- Surveillance proactive : mettre en place une veille sur les enregistrements de domaines similaires (variantes de TLD, sous-domaines) et agir rapidement en cas d’usurpation.
- Enregistrement stratégique : lorsque cela est pertinent, enregistrer les variantes de TLD majeures ou sensibles pour éviter qu’elles ne soient utilisées par des tiers malveillants.
- Utiliser les outils officiels : vérifier et gérer les propriétés via Google Search Console et autres interfaces éditeur pour démontrer la propriété du contenu et aider les algorithmes à associer correctement le nom de marque au domaine officiel.
- Signaler les abus : escalader auprès des registres TLD, des hébergeurs ou des plateformes publicitaires les domaines qui enfreignent des règles (contenu illicite, phishing, violation de marque).
Pour les utilisateurs
- Vérifier l’URL : lorsqu’une source proposée semble familière, contrôler l’extension du domaine (.com, .co, .in, etc.) et préférer l’adresse officielle du média.
- Prudence face aux contenus suspects : si une source recommandée propose des liens vers des offres trop agressives ou des pages peu informatives, considérer qu’il s’agit peut‑être d’un domaine opportuniste.
- Préférence pour les sites vérifiés : privilégier les médias qui affichent une page « À propos », des informations de contact et des mentions légales cohérentes, signes de légitimité éditoriale.
Pourquoi certains domaines n’ont que la page d’accueil indexée ?
L’observation selon laquelle plusieurs domaines apparentés n’ont que leur page d’accueil indexée peut résulter de plusieurs facteurs techniques et éditoriaux :
- Contenu mince : si un site ne comporte que très peu de pages substantives ou si son contenu est généré automatiquement et peu riche, l’indexation des pages internes est souvent limitée par les algorithmes de Google.
- Restrictions techniques : des directives
robots.txtmal configurées, des balisesnoindexou des erreurs serveur peuvent empêcher l’indexation correcte des pages. - Intention malveillante : certains domaines sont créés uniquement pour héberger une page d’accueil monétisée (landing page) et ne visent pas à produire des rubriques éditoriales ; l’indexation se limite alors à cette page principale.
- Nouveauté du domaine : un domaine nouvellement enregistré peut n’avoir que sa page d’accueil indexée dans un premier temps, surtout si la publication de contenu étendu n’a pas encore eu lieu.
Cette situation est souvent révélatrice d’un site qui n’a pas vocation à être un média d’information à part entière, ce qui renforce l’argument pour un filtrage plus strict dans la liste des Preferred Sources.
Aspects juridiques et de marque
Les pratiques de domain squatting et d’enregistrement de variantes proches posent aussi des questions juridiques. Les détenteurs de marques disposent de recours : procédures de règlement des litiges (UDRP et autres mécanismes de contestation auprès des registres), actions en contrefaçon ou signalements auprès des autorités compétentes. Cependant, ces démarches prennent du temps et ne constituent pas une panacée face à la multiplication rapide des enregistrements.
Au-delà de la voie judiciaire, la coopération entre les registres, les plateformes d’hébergement et les moteurs de recherche peut accélérer la suppression ou la neutralisation de domaines manifestement frauduleux. Une meilleure coordination permettrait de réduire l’exploitation commerciale des noms de marque par des tiers non autorisés.
Considérations techniques pour la détection automatique
Du point de vue algorithmique, plusieurs indicateurs peuvent être intégrés pour améliorer la robustesse des sélections de sources :
- Profondeur d’indexation : la présence d’un nombre significatif de pages indexées avec du contenu original et des signaux d’autorité (backlinks, mentions sociales) est un indicateur de qualité.
- Signature éditoriale : détection de structures d’articles (titres, métadonnées, datation, auteur) et évaluation de la cohérence éditoriale sur plusieurs pages.
- Vérification de la propriété : corrélation avec des comptes certifiés, profils sociaux officiels et enregistrements dans des services d’agrégation reconnus.
- Historique du domaine : un domaine récemment enregistré et immédiatement utilisé pour de la publicité agressive ou des pages fines est suspect. Les délais d’attente ou de contrôle peuvent réduire les abus.
L’intégration de ces signaux dans le processus d’éligibilité des Preferred Sources permettrait de limiter les apparitions de domaines opportunistes tout en préservant la diversité des sources légitimes.
Observations finales
La fonctionnalité Preferred Sources a pour ambition d’offrir aux lecteurs un contrôle accru sur l’apparence de leur flux d’actualités dans Top Stories, mais elle présente aujourd’hui des failles exploitables par des acteurs peu scrupuleux. La présence de domaines copycat, de sites parkés ou de pages à contenu limité dans la liste des sources préférées nuit à la confiance des utilisateurs et crée des risques pour la réputation des médias.
Pour restaurer cette confiance, une combinaison de mesures techniques (filtrage, vérification), de politiques (processus de signalement, transparence) et d’actions proactives de la part des éditeurs (surveillance, protection de marque) est nécessaire. De plus, une plus grande transparence sur les critères d’admission et des voies claires pour signaler les abus aideraient à limiter la diffusion de domaines frauduleux via cet outil.
En attendant des améliorations, la vigilance reste de mise : vérifier les URLs, s’assurer de la légitimité des sources et signaler les anomalies permettra de réduire l’efficacité de ces pratiques d’usurpation.
Pour consulter la page de préférences concernée, on peut se rendre sur la page officielle des sources préférées de Google : préférences de sources Google.
Services associés


