Ce billet a été sponsorisé par TAC Marketing. Les opinions exprimées ici sont celles du sponsor.
Après des années à tenter de percer le fonctionnement parfois opaque de la recherche Google, les spécialistes du référencement font face à aujourd’hui un défi encore plus nébuleux : comment obtenir des **citations IA** dans les réponses générées par les assistants et moteurs alimentés par l’**IA**.
À première vue, apparaître dans les réponses d’un modèle d’**IA** paraît plus mystérieux que le référencement traditionnel, mais il existe des éléments concrets à observer. Une fois que l’on sait où chercher, les moteurs et leurs **crawlers** laissent des indices sur les types de **contenu** qu’ils jugent utiles.
Ce guide détaille une méthode pas à pas pour identifier le **contenu** privilégié par les moteurs d’**IA** et propose un plan pratique pour optimiser votre site en vue d’obtenir des **citations IA**.
Adopter une méthode systématique pour l’optimisation IA
Construire une stratégie d’**optimisation IA** efficace exige d’abord d’observer précisément le comportement des **crawlers** des plateformes d’**IA**. En analysant leurs visites, vous découvrez quelles pages et quels formats de **contenu** sont considérés comme intéressants par ces systèmes, puis vous pouvez élaborer des actions fondées sur des données réelles.
Si Google reste un acteur majeur, des moteurs et assistants alimentés par l’**IA** comme ChatGPT, Perplexity ou Claude sont de plus en plus utilisés par des internautes en quête de réponses instantanées et synthétiques. Ces systèmes ne génèrent pas leurs réponses ex nihilo : ils s’appuient sur des sources web indexées et, parfois, sur des récoltes de données spécifiques menées par leurs propres **crawlers**.
Cela crée à la fois une opportunité et une contrainte. L’opportunité : positionner votre **contenu** pour qu’il soit consulté et cité par ces systèmes. La contrainte : comprendre et optimiser pour des algorithmes qui ne fonctionnent pas exactement comme les moteurs de recherche traditionnels.
La réponse : une démarche systématique et itérative
- Identifier le **contenu** valorisé par les moteurs d’**IA** via l’observation des **crawlers**.
- Analyse classique des fichiers journaux (logs).
- Solutions simplifiées de surveillance des **crawlers**, intégrées aux CMS.
- Reconstituer les signaux utilisés par les modèles.
- Analyse du **contenu** (format, structure, entités).
- Analyse technique (balises, accès, schéma de lien interne, données structurées).
- Construire un plan d’action reproductible.
Que sont les crawlers d’**IA** et comment en tirer parti
Les crawlers d’**IA** sont des robots automatisés déployés par des entreprises d’**IA** pour parcourir et ingérer des pages web. À la différence des robots de recherche traditionnels qui priorisent principalement des signaux de classement, ces **crawlers** récoltent des extraits de **contenu** afin d’entraîner des modèles linguistiques ou d’alimenter des bases de connaissances servant à produire des réponses.
Parmi les principaux **crawlers** cités par les acteurs du secteur :
- GPTBot (lié à ChatGPT d’OpenAI).
- PerplexityBot (Perplexity AI).
- ClaudeBot (Anthropic).
- Les variantes de Googlebot employées pour des fonctionnalités IA de Google.
Ces robots influencent votre stratégie de **contenu** selon deux axes majeurs :
- Collecte de données d’entraînement.
- Récupération d’informations en temps réel.
Collecte de données d’entraînement
Les modèles de langage sont nourris par d’énormes volumes de pages web. Les pages fréquemment parcourues par les **crawlers** risquent d’être surreprésentées dans les jeux de données, ce qui augmente la probabilité que leur information soit reprise par la suite dans des réponses générées.
Récupération d’informations en temps réel
Certaines plateformes effectuent des requêtes en direct sur le web pour actualiser leurs réponses. Un **contenu** récent et aisément accessible peut donc être consulté par ces systèmes et cité dans une réponse immédiate.
Quand, par exemple, ChatGPT propose une synthèse à un utilisateur, il s’appuie sur des informations collectées par ses **crawlers** et sur des indexation internes. De même, Perplexity AI se distingue par sa capacité à fournir des sources citées, ce qui implique un processus actif de crawling et d’analyse. Claude s’appuie aussi sur de larges collectes de données pour construire ses réponses.
La présence et l’intensité d’activité de ces **crawlers** sur votre site conditionnent directement votre visibilité dans ces écosystèmes : elles déterminent si vos pages sont retenues comme sources, si elles servent à informer des réponses et si vous pouvez en obtenir une attribution ou un flux de trafic vers votre site.
Comprendre quelles pages sont le plus souvent explorées par les **crawlers** vous donne une vision fine des signaux qui intéressent les modèles d’**IA**. Ces observations constituent la matière première pour orienter votre stratégie d’optimisation.
Suivre l’activité des crawlers IA : utilisation de l’analyse des logs
L’approche éprouvée : l’examen des journaux serveur reste la méthode la plus complète pour cerner la fréquentation des robots, y compris les **crawlers** d’**IA** qui n’apparaissent pas nécessairement dans les outils d’analyse classique centrés sur le trafic humain.
Vos fichiers de logs enregistrent chaque requête adressée au serveur : en les analysant, on peut repérer des chaînes user-agent correspondant aux **crawlers** d’**IA** et mesurer leur comportement (pages visitées, fréquence, pattern horaire, etc.).
Outils recommandés pour l’analyse des logs
Plusieurs outils de niveau professionnel permettent de traiter des fichiers de logs volumineux et de produire des rapports exploitables :
- Screaming Frog Log File Analyser : adapté aux spécialistes techniques à l’aise avec la manipulation de données.
- Botify : solution d’entreprise pour l’analyse approfondie des crawls.
- Semrush : propose des fonctions d’analyse des logs intégrées à sa suite SEO.
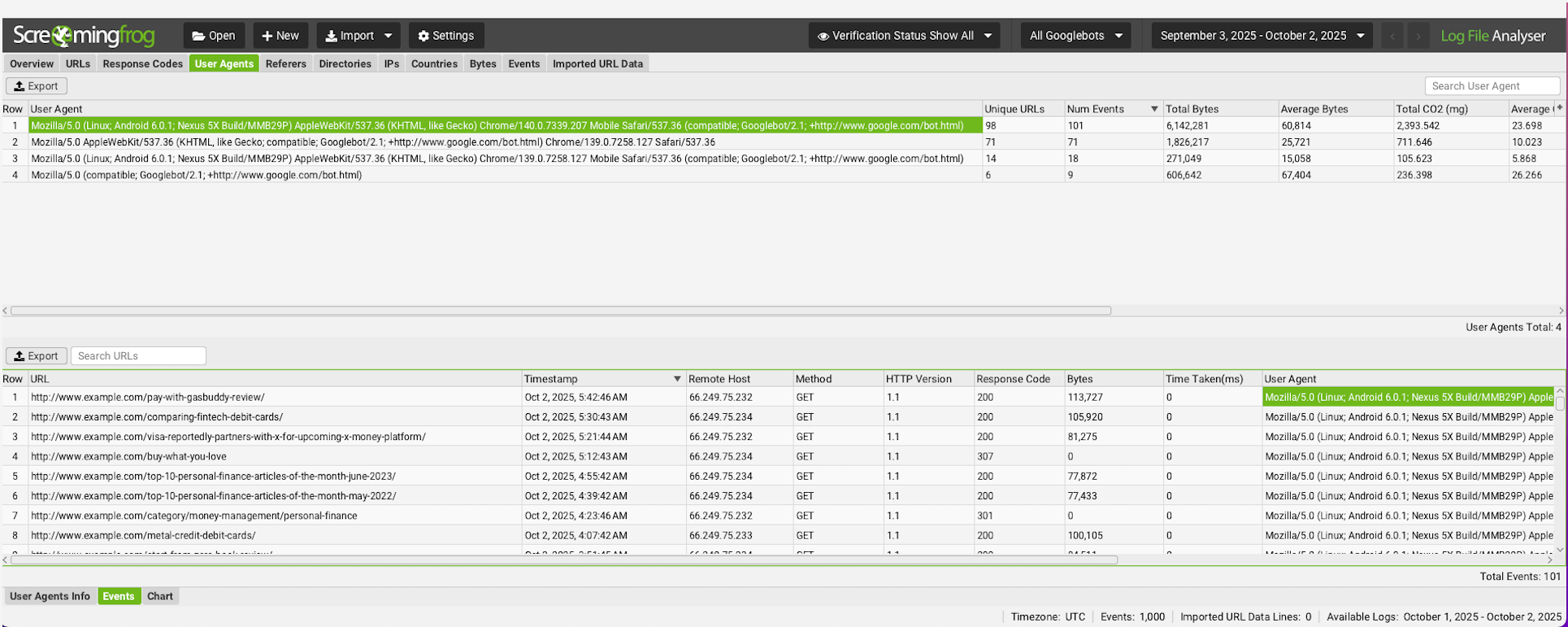 Screenshot from Screaming Frog Log File Analyser, October 2025
Screenshot from Screaming Frog Log File Analyser, October 2025Les difficultés pratiques de l’analyse des logs
L’analyse des logs reste la source la plus granulaire pour comprendre quels robots parcourent votre site, quelles URL ils consultent et à quelle cadence. Mais cette méthode présente plusieurs obstacles :
- Accéder aux fichiers : les logs se trouvent généralement dans le panneau d’hébergement ou sur le serveur via SSH/FTP (fichiers Apache access logs, Nginx access logs, etc.).
- Identifier les user-agents : il faut connaître les chaînes d’identification des **crawlers** que vous recherchez, lesquelles peuvent évoluer dans le temps. Exemples fréquents :
- OpenAI (utilisés par certains services ChatGPT, p. ex. `ChatGPT-User` ou variantes).
- Perplexity AI (p. ex. `PerplexityBot`).
- Anthropic (pour Claude, parfois moins explicite ou masqué derrière des agents cloud).
- Divers robots liés aux LLMs (parfois des variantes de `Googlebot`, `Google-Extended`, ou des agents de fournisseurs cloud comme `Vercelbot` intervenant pour des requêtes ponctuelles).
- Traiter et visualiser : importez vos logs dans un analyseur dédié pour filtrer et isoler l’activité des **crawlers** d’**IA**. Les équipes techniques peuvent aussi automatiser ces étapes via des scripts Python, Splunk, Elasticsearch ou d’autres plateformes d’analyse.
Cependant, ces bénéfices s’accompagnent de contraintes non négligeables :
- Complexité technique : nécessite un accès serveur, la connaissance des formats de logs et des compétences en parsing.
- Ressources : les sites volumineux produisent de très grands fichiers qui peuvent être lourds à traiter.
- Temps : mettre en place un workflow robuste demande un investissement initial en temps et en expertise.
- Identification : distinguer précisément chaque **crawler** requiert une veille sur les user-agents et leur évolution.
Pour les équipes sans développeurs dédiés, ces barrières rendent parfois l’analyse des logs difficile malgré sa valeur.
Une méthode simplifiée pour surveiller les visites IA
Face à la complexité de l’analyse des logs, des solutions plus accessibles existent pour obtenir des indications exploitables sur l’activité des **crawlers** d’**IA**.
Parmi elles, le plugin WordPress SEO Bulk Admin est souvent cité comme un exemple d’outil qui détecte et affiche les visites de plusieurs **crawlers** majeurs directement depuis l’interface du site, sans manipulation directe des fichiers logs.
Les fonctionnalités rapportées par ce type d’outil comprennent :
- Détection automatisée : reconnaissance (plutôt que configuration manuelle) de certains **crawlers** tels que GPTBot, PerplexityBot et ClaudeBot.
- Tableau de bord accessible : présentation visuelle des visites, compréhensible par des équipes marketing et éditoriales.
- Surveillance en quasi-temps réel : enregistrement des visites des robots au fur et à mesure.
- Analyse par page : indication des pages les plus consultées par ces robots, ce qui facilite les décisions éditoriales.
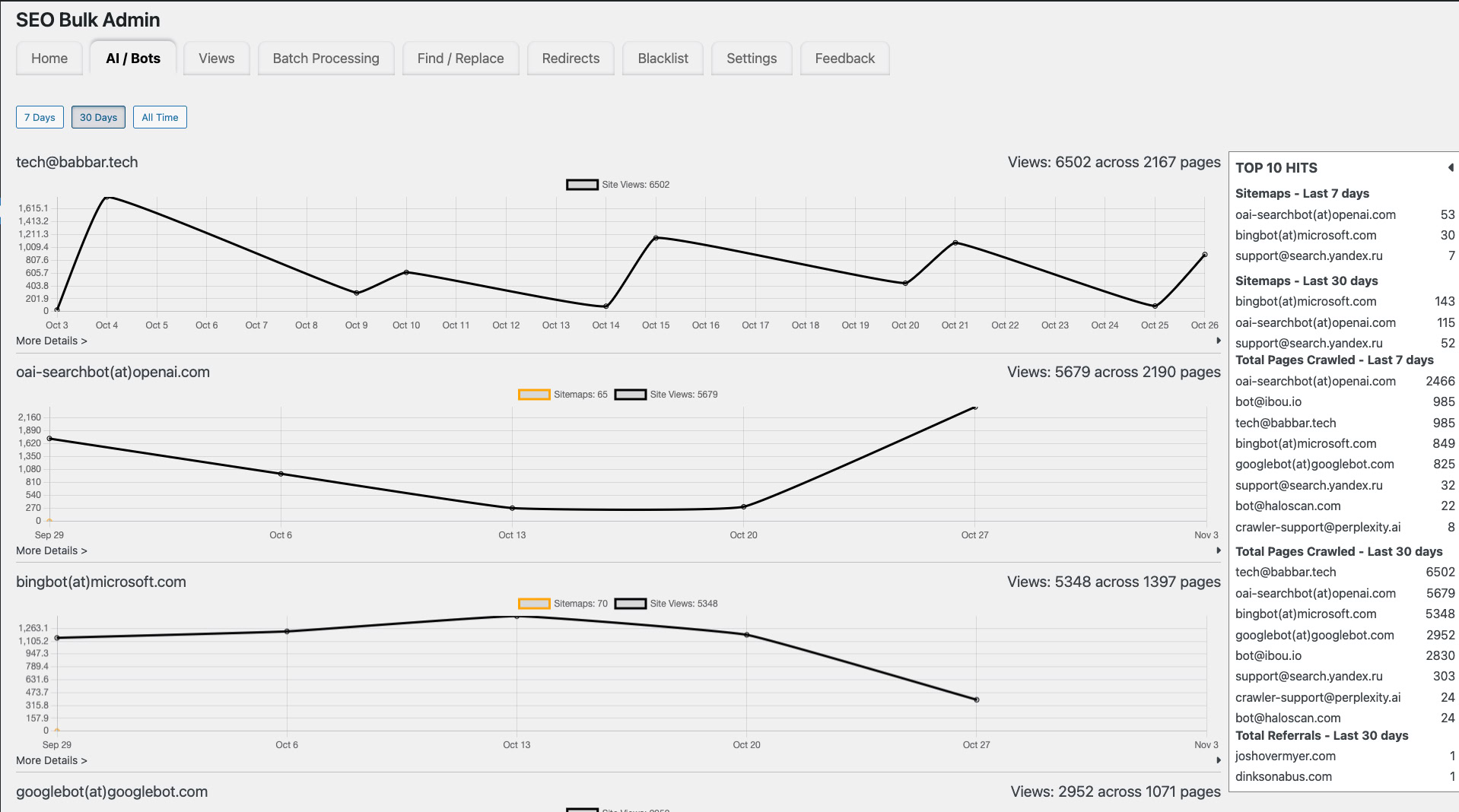 Screenshot of SEO Bulk Admin AI/Bots Activity, October 2025
Screenshot of SEO Bulk Admin AI/Bots Activity, October 2025De façon pragmatique, ces outils offrent une visibilité immédiate sur les pages consultées par les **crawlers** sans exiger de compétences serveur approfondies.
Comparaison : analyse des logs vs. SEO Bulk Admin
| Critère | Analyse des logs | SEO Bulk Admin |
| Source de données | Fichiers logs bruts | Tableau de bord WordPress |
| Installation technique | Élevée | Faible |
| Identification des robots | Manuelle | Automatique |
| Suivi des crawls | Très détaillé | Automatisé |
| Adapté pour | Équipes SEO d’entreprise | Équipes éditoriales et marketeurs |
Pour des équipes qui n’ont pas accès aux logs, des solutions intégrées au CMS telles que SEO Bulk Admin peuvent servir de source d’information pratique et en temps rapproché sur l’activité des **crawlers**, facilitant des décisions éditoriales basées sur des données observées.
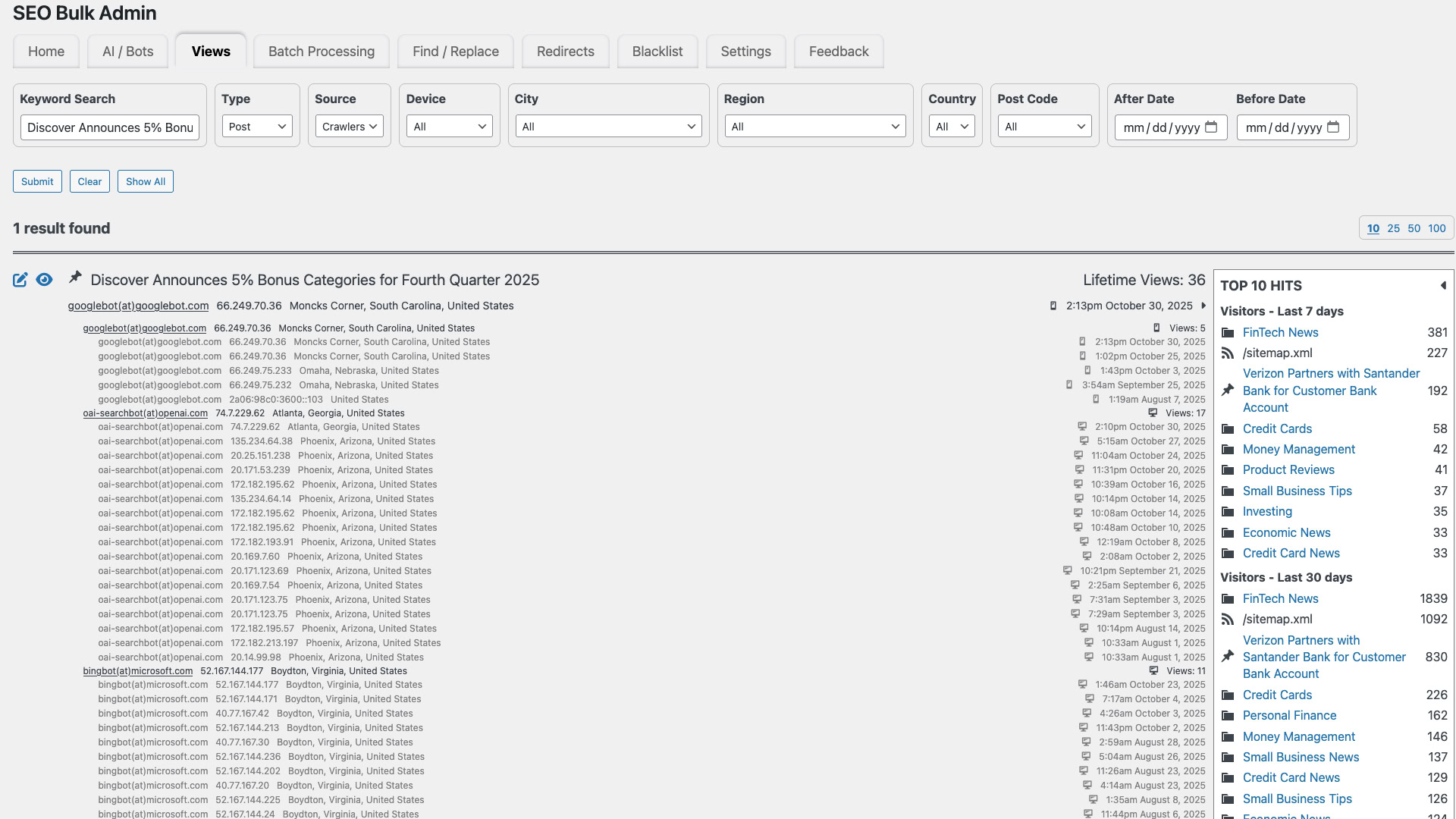 Screenshot of SEO Bulk Admin Page Level Crawler Activity, October 2025
Screenshot of SEO Bulk Admin Page Level Crawler Activity, October 2025Exploiter les données des crawlers IA pour améliorer la stratégie de contenu
Dès que vous collectez des informations sur l’activité des **crawlers**, le travail d’optimisation peut commencer. Les données de crawl révèlent des tendances exploitables qui transforment la prise de décision éditoriale : on passe de l’intuition à une démarche guidée par l’observation des machines.
Voici des étapes concrètes pour tirer parti de ces informations :
1. Repérer les pages privilégiées par l’**IA**
- Pages à haute fréquence de crawl : identifiez les URL que les **crawlers** visitent le plus. Ces pages sont celles que les robots consultent régulièrement, ce qui peut indiquer qu’elles sont jugées pertinentes, fréquemment mises à jour ou informatives pour des requêtes traitées par les modèles.
- Formats privilégiés : notez si des types de pages spécifiques — guides pratiques, pages de définitions, résumés de recherche ou FAQ — attirent davantage les **crawlers**. Cela renseigne sur le type d’information que les modèles recherchent.
2. Détecter les caractéristiques favorisées par les LLM
- Usage de données structurées : observez si les pages les plus crawlées intègrent des données structurées (balises Schema). Bien que le rôle exact des Schema dans le comportement des modèles reste débattu, ces balises facilitent l’extraction d’informations précises.
- Clarté et concision : les modèles traitent mieux les textes clairs et sans ambiguïté. Les pages favorisées présentent souvent des réponses directes, des paragraphes courts et une segmentation thématique claire.
- Autorité et références : les pages perçues comme fiables — citées ou sourcées — attirent souvent plus d’attention. Vérifiez si les pages reconnues comme pertinentes disposent d’appuis documentaires ou de liens vers des sources crédibles.
3. Construire un modèle à partir des contenus performants
- Reproduire les succès : pour chaque page fortement crawlée, documentez ses attributs distinctifs.
- Structure du texte : hiérarchie des titres, sous-titres, listes à puces, paragraphes courts.
- Format : proportions texte/multimédia, inclusion de tableaux, d’infographies, de blocs Q&A.
- Profondeur thématique : contenu exhaustif vs. articles concis sur une niche précise.
- Mots-clés et entités : termes récurrents, personnes, organisations, dates, chiffres.
- Implémentation de données structurées : quels types de Schema sont présents (Q&A, HowTo, Article, FactCheck, etc.).
- Liens internes : schéma de maillage et pages piliers liées.
- Améliorer les pages moins visitées : appliquez les caractéristiques des pages performantes aux contenus sous-exploités.
- Réorganiser : fractionnez les paragraphes denses, ajoutez des sous-titres et des listes pour faciliter l’extraction d’informations.
- Ajouter des données structurées : implémentez les Schema pertinents pour améliorer la lisibilité automatique.
- Rendre le texte plus net : reformulez pour des réponses concises et directement utiles, en ciblant les questions des utilisateurs.
- Renforcer l’autorité : ajoutez des sources fiables, des références et des mises à jour factuelles.
- Optimiser le maillage interne : assurez-vous que les pages performantes relaient le jus vers les pages à développer, créant ainsi des clusters thématiques.
La vidéo suivante montre concrètement comment identifier les pages les plus souvent parcourues par les **crawlers** d’**IA** et comment exploiter ces informations pour commencer une stratégie d’optimisation.
Voici le prompt utilisé dans la démonstration :
Vous êtes un expert en SEO centré sur l’**IA** et l’analyse du comportement de crawl.
TÂCHE : Analyser et expliquer pourquoi l’URL [https://fioney.com/paying-taxes-with-a-credit-card-pros-cons-and-considerations/] a été crawlée 5 fois au cours des 30 derniers jours par le crawler oai-searchbot(at)openai.com, alors que [https://fioney.com/discover-bank-review/] n’a été crawlée que deux fois.
OBJECTIFS :
– Diagnostiquer les facteurs techniques pouvant augmenter la fréquence de crawl (ex. : maillage interne, signaux de fraîcheur, priorité dans le sitemap, données structurées, etc.)
– Comparer les signaux de niveau contenu comme l’autorité thématique, l’aptitude à être cité, ou l’alignement avec les besoins de citation des LLM
– Évaluer comment chaque page se comporte comme source potentielle de citation (ex. : spécificité, utilité factuelle, originalité)
– Identifier les signaux de classement et de visibilité qui peuvent influencer la priorisation des crawls par des indexeurs IA comme OpenAI
CONTRAINTES :
– Ne pas supposer le comportement des utilisateurs ; se concentrer sur les signaux algorithmiques et de contenu uniquement
– Utiliser des puces ou un tableau comparatif
– Pas de conseils SEO génériques ; adapter la sortie spécifiquement aux URL fournies
– Prendre en compte les tendances récentes de citation par les LLM et les priorités des systèmes de contenu utile
FORMAT :
– Partie 1 : comparaison technique SEO
– Partie 2 : comparaison du niveau contenu pour la valeur de citation IA
– Partie 3 : recommandations actionnables pour augmenter le taux de crawl et le potentiel de citation de l’URL la moins visitée
Fournir uniquement l’analyse, sans commentaires ni résumé.
Remarque : d’autres formulations de prompts et ressources pour l’optimisation axée sur l’**IA** sont disponibles dans cet article : 4 prompts pour favoriser les citations IA.
En vous appuyant sur une démarche fondée sur des données de crawl, vous sortez du registre de l’hypothèse et construisez une stratégie de contenu adaptée au comportement réel des machines sur votre site.
Le cycle itératif d’observation, d’analyse et d’amélioration permet de maintenir vos pages comme des ressources pertinentes et faciles à exploiter par les moteurs et assistants d’**IA** en évolution.
Conclusions et perspectives pour l’optimisation IA
Surveiller et analyser l’activité des **crawlers** d’**IA** n’est plus un luxe pour les équipes SEO qui veulent rester visibles dans l’écosystème des recherches conversationnelles et des assistants. C’est devenu une pratique essentielle pour comprendre comment et pourquoi certaines pages sont utilisées comme sources par les modèles.
Qu’il s’agisse d’une analyse des logs poussée ou d’outils intégrés au CMS comme SEO Bulk Admin, l’objectif reste le même : s’appuyer sur des données observées pour prioriser les améliorations techniques et éditoriales.
Adoptez une attitude proactive : identifiez les tendances d’activité des **crawlers**, renforcez vos contenus les plus visités et appliquez les apprentissages aux pages moins performantes. Travaillez la clarté, la structure, l’actualité et la crédibilité des pages pour accroître vos chances d’apparaître comme source de référence dans les réponses générées par l’**IA**.
Avec l’**IA** qui occupe une place croissante dans l’accès à l’information, adapter vos pratiques éditoriales et techniques vous permettra d’optimiser de nouvelles opportunités de visibilité et de valorisation de votre **contenu**.
Crédits images
Image à la une : Image par TAC Marketing. Utilisée avec permission.
Images dans l’article : Image par TAC Marketing. Utilisée avec permission.
